반응형

Introduction
[문제]
- Python은 매우 간단하고, 응용 모듈이 많아서, 많이 선호되지만, 속도가 중요한 프로그램에서는 항상 문제가 된다.(Python 코드의 속도 튜닝의 끝은 다른 언어로 다시 개발하는 것이라고 할 만큼, Python은 느리다.)
- 하지만, Python에만 존재하는 응용 패키지들이 많아서, Python 언어를 유지하면서 속도 튜닝이 필요한 경우가 많다.
- Python이 느린 이유는 많지만, 아래의 이유가 치명적이다.
- 인터프리터 언어 : 코드를 한줄 씩 읽고, 해석하는 식으로 동작한다.
- 동적 타이핑 : Python은 형식을 지정해주지 않아, 코드 실행 중에 Type 지정이 필요하다.
[Numba]
- Numba는 이러한 Python의 실행 속도를 개선하기 위한 대표적인 라이브러리로, JIT(just-in-time)이라는 Compiler를 통해, Numpy 배열, 함수, loop의 속도를 개선하였다.
- 단순히, 패키지 import와 decorator 사용만 하면 되어서, 매우 간단하다.
- Numba는 Array 처리 등의 무거운 Python 코드를 동적으로 compile 하여, 기계어로 변환한다. 이 과정에서 type 정보 분석 & 최적화를 하여, 속도를 최적화한다.
Numba 설치 방법
- Numba의 설치 방법은 매우 간단하다.
pip install numba또는
conda install numba- 다만, numpy array를 최적화하는 라이브러리인 만큼, numpy에 대한 version 의존성이 있다. https://numba.readthedocs.io/en/stable/user/installing.html를 참조해서 맞는 버전을 설치하는 것을 추천한다.
Numba 사용
- numba는 기본적으로 함수에 @jit의 decorator를 넣어주면 된다.
from numba import jit
@jit
def numba_func(input):
sol = np.tanh(input)
return sol- numba에는 몇 가지 옵션을 사용할 수 있는데, 각 옵션은 다음과 같다. (해당 옵션등은 함께 적용할 수 있다.)
| Option 명 | 설명 | 주의점 | 사용 예시 |
| nopython | Python을 interpreter로 처리하지 않고, Compile을 진행 | Python에서만 존재하는 라이브러리(pandas 등)를 사용하면 Error가 뜸 | @jit(nopython=True) |
| nogil | GIL(Global Interpreter Lock)을 사용하지 않음. | Thread 간 안전성 문제가 있을 수 있음, 메모리 사용량이 많아질 수 있음 | @jit(nogil=True) |
| cache | Compile 결과를 디스크에 캐싱하여, 이후에 재사용 할 수 있도록 함 | Numba 버전이나, 코드 변경 시, 캐시 파일이 의미가 없을 수 있음. | @jit(cache=True) |
| parallel | 병렬 처리를 위해 사용, 반복문과 배열의 연산을 병렬화하여 cpu 코어를 활용 가능 | 추가적인 메모리 사용과 오버헤드 발생 가능, 병렬화로 인해 항상 성능 향상을 보장하지 못함. | @jit(parallel=True) |
- 일반적으로 nopython 모드를 True로 하는 경우가 많다. 이것은 Python interpreter와 상호작용을 최소화하여, 함수를 빠르게 수행할 수 있기 때문이다.
- nopython 모드는 자주 사용되기 때문에 njit decorator를 통해 사용되기도 한다.
from numba import njit
//@jit(nopython=True)와 같음
@njit
def numba_func(input):
sol = np.tanh(input)
return sol- numba는 jit 이외에도 stencil과 같은 다양한 함수들을 지원한다. 자세한 내용은 홈페이지(https://numba.readthedocs.io/en/stable/index.html)를 참고하는 것이 좋을 것 같다
Numba 성능 비교
- H/W와 코드 환경, 연산하는 함수에 따라, 컴파일 및 최적화 정도는 천차만별이다. 따라서, 절댓값이 주목하기보다는 대략적으로 이런 효과가 있구나 정도로 생각해 주길 바란다.
import numpy as np
from numba import jit
import time
@jit
def numba_func(input):
sol = np.tanh(input)
return sol
def no_numba_func(input):
sol = np.tanh(input)
return sol
if __name__ == '__main__':
data_length = 1000000000
input_data = np.arange(data_length)
start_time = time.time()
numba_func(input_data)
end_time = time.time()
print("Elapsed Time (with numba):",end_time-start_time)
start_time = time.time()
no_numba_func(input_data)
end_time = time.time()
print("Elapsed Time (without numba):",end_time-start_time)- 길이가 10억개의 데이터에 대해서 jit과 jit 옵션이 없는 코드를 실행해 보았다. jit을 사용한 것이 빠른 속도를 보여주는 것을 확인할 수 있다.
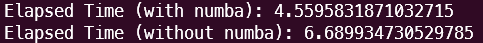
- 길이가 1억개의 데이터에 대해서 jit과 jit 옵션이 없는 코드를 실행해 보았다. jit을 사용하지 않은 것이 더 빠른 속도를 보여주는 것을 확인할 수 있다.
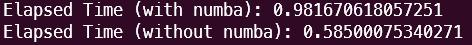
- 길이가 1000개 정도의 소규모(?) 데이터에서 실행 결과, jit의 overhead가 확실히 존재한다는 것을 확인할 수 있다.

→ 다만, JIT의 성능 향상에 대한 연산량은 H/W 등의 실험환경에 크게 영향을 받는다. 꼭, 실제 코드를 돌릴 환경에서 테스트해 보고 적용하는 것을 추천한다.
Numba 주의점
- Numba는 대용량의 연산이 아닌, 소규모의 연산에서는 오히려 느린 성능을 보여준다. 이는 Numba의 JIT 컴파일에 약간의 오버헤드가 있기 때문이다.
- Numba에서 성능 향상을 보기 위해서는, 최대한 간단하고, 배열 위주의 작업들을 대용량 데이터에서 사용해야한다. 제어 흐름이 복잡한 코드는 최적화에 한계가 있다.
- nopython 옵션 적용 시, JIT이 컴파일 할 수 없는 경우에는 에러가 뜬다. Input과 Output의 타입, 함수 내의 연산이 명확한 경우에만 사용하도록 한다.
- Numba가 효과있는 데이터 양등을 실제 프로그램이 돌아갈 환경에서 실험해 보고, 데이터 연산량을 대략적으로 계산하여, JIT을 적용한 함수와 적용하지 않는 함수를 각각 놓고 분기를 치는 것도 좋은 방법이다.
- 실제로 운영 단에 있는 코드 들에서는 하나의 함수에 복잡한 내용이 섞여있는 경우가 많다. 이러한 경우, numpy나 for문만 별도의 함수로 나눠서 JIT을 적용해줘야한다. 이러한 변경은 최적화에서는 이점이 있을지 모르지만, 가독성에서는 해가될 수 있다.
Numba는 Python의 고질 병인 속도 문제를 해결하기 위해, 등장한 라이브러리다. 비록, 대용량 데이터에서만 효과를 볼 수 있다는 아쉬운 점도 있지만, 이런 옵션이 존재한다는 것이 어딘가 싶다. (사실, 대용량 데이터가 아니면, 굳이 속도 문제가 치명적이진 않을 것이다.) 만약, 운영 환경에서 간혹 존재하는 대용량 데이터에 고통받고 있다면, 예외처리용으로 사용해도 좋을 것 같다.
'Python' 카테고리의 다른 글
| Pandas 성능 향상을 위한 방법들 (2) | 2023.07.21 |
|---|---|
| Transformer Pytorch 구현 (12) | 2023.07.15 |
| Pytorch Profiler Tensorboard로 시각화 (1) | 2023.07.10 |
| Pytorch Resource & 모델 구조 Profiler 도구 (torch profiler) (1) | 2023.07.09 |
| Python 프로파일링을 위한 도구들 (Process, Memory, Execution Time) (5) | 2023.07.06 |



