패키지를 설치하다 보면, 의존성이 꼬이는 경우가 많다. 이런 경우, pip install --upgrade를 사용하는 방법도 있지만, 아예 package를 지우고 다시 설치하는 편이 좋은 경우도 있는데, uninstall을 통해 삭제한다.
pip uninstall을 하면, 해당 패키지를 위해 설치되었던, 의존성 있는 라이브러리들은 잔존하게 되는데, 이것은 pip-autoremove를 통해 모두 삭제할 수 있다.
pip uninstall {패키지명}
pip install pip-autoremove #패키지 설치
pip-autoremove {패키지명}
설치 가능한 패키지 조회
기존에는 pip search를 통해, 특정 패키지의 설치 가능한 모든 버전을 확인할 수 있었다.
하지만, 너무 많은 API call이 있어서, 지원을 멈췄다고 한다.
설치 가능한 패키지를 확인하는 방법은 pypi.org(https://pypi.org/)에 접속하여, 직접 검색해 보는 것 밖에 없다. (예전 버전은 pip search {패키지명} 사용하면 된다.)
설치된 패키지 조회
pip list는 현재 환경 (local or 가상환경) 내에 존재하는 패키지들과 각 패키지의 버전을 나열해 준다.
pip freeze도 pip list처럼 설치된 패키지 목록을 출력하지만, requirements.txt를 바로 구성할 수 있는 형태로 출력된다.
따라서, pip freeze를 requirements.txt로 export 하고, 다른 환경에서 install 하면 현재 가상환경의 pypi 패키지들을 그대로 설치할 수 있다. (테스트 환경 구축 시 많이 활용한다.)
pip list
pip freeze
pip freeze > requirements.txt
pip listpip frreze
의존성 확인
계속 언급하듯, pypi 내에서는 의존성이 꼬이는 경우가 많다.(가상환경이 자주 쓰이는 이유이다.)
물론, 설치 시에 의존성에 대한 문제를 제기하겠지만, 당장 실행되면 넘어가는 경우가 많다.
이렇게 의존성이 꼬이는 경우가 많아, 의존성을 check 하기 위한 명령어가 존재하는데, 바로 pip check이다.
pip check
폐쇄망 Pypi 사용법
pypi는 기본적으로 원격 저장소에서 패키지를 가져오는 것이기 때문에, 인터넷 연결이 존재해야 한다.
아예 오프라인 환경이나, 방화벽 등에 의해, 원격 저장소에 접근하지 못하는 환경에서는 단순 pip install을 이용하여 설치가 불가능하다.
우선, 프락시 서버가 있는 경우에는 아래와 같이 proxy 서버를 명시하여 사용할 수 있다.
pip install --proxy {proxy 서버 IP}:{proxy 서버 port} {패키지명}
proxy 서버도 존재하지 않는 경우에는 인터넷 망에서 패키지를 설치하고, 오프라인 환경에서 빌드하여 사용하는 방법을 사용할 수 있다.
우선 인터넷망에서 pip download를 통해, 패키지를 빌드 전 파일로 내려준다.
설치된 파일들을 USB 등을 통해, 폐쇄망 서버로 옮기고, 아래와 같이 --no-index(index 서버를 사용하지 않겠다는 뜻)와 --find-link 명령어를 포함한 pip install 명령어를 통해 설치해 준다.
download를 하나하나 하기 귀찮다면(보통은 의존성 때문에), pip freeze를 이용하여, requirement 형태로 떨군 후, pip download -r requirements.txt를 이용하여, 모든 패키지를 설치하고, 이 패키지를 폐쇄망에서 설치하는 방법도 있다.
(인터넷망) pip download {패키지명}
(폐쇄망) pip install --no-index --find-links={패키지 파일 저장 경로}
Python으로 짜인 Code를 서비스하다 보면, CPU 100%나 Memory Fault, 실행시간이 길어지는 등 다양한 문제를 만나게 된다.
자신이 개발한 코드에서는 직감적으로 어느 부분이 문제가 될지를 간파할 수 있지만, 다른 사람이 짠 코드에서 문제에 원인이 되는 부분을 찾아내기는 매우 어렵다.
일반적으로 가장 쉽게 떠올릴수 있는 방법은 실행시간은 time 모듈을 이용한 print 디버깅이나 unittest, CPU나 memory는 작업 관리자를 통해 확인하는 방법이다. 하지만, 이 방법들은 대략적인 정도만 알아낼 수 있고, 어느 부분이 문제가 있는지 진단하기 매우 어렵다.
Python에서는 Profiling을 위한 다양한 도구들을 가지고 있어, code 분석이 매우 용이하다. 어떤 것들이 있는지 확인해보자!
Code Sample
각 도구들을 Test 하기 위한 sample code이다.
code는 각각 validation_check, data_preprocessing, outlier_remove, data_sort, data_cal_half_avg 함수를 거쳐 최종 결과를 내도록 되어있다.
import numpy as np
def data_validation_check(sensor_value):
try:
for i in sensor_value.split("|"):
float(i)
return True
except:
print("Error")
return False
def data_preprocessing(sensor_value):
sensor_value = sensor_value.split("|")
sensor_value = list(map(float, sensor_value))
return sensor_value
def outlier_remove(sensor_value):
data_mean = np.mean(sensor_value)
data_std = np.std(sensor_value)
lower_bound = data_mean - 3 * data_std
upper_bound = data_mean + 3 * data_std
sensor_value = [i for i in sensor_value if lower_bound < i and upper_bound > i]
return sensor_value
def data_sort(sensor_value):
return np.sort(sensor_value)
def data_cal_half_avg(sensor_value):
return np.mean(sensor_value[int(len(sensor_value) * 0.5):])
def run(sensor_value):
if data_validation_check(sensor_value):
sensor_value = data_preprocessing(sensor_value)
sensor_value = outlier_remove(sensor_value)
sensor_value = data_sort(sensor_value)
sol = data_cal_half_avg(sensor_value)
return sol
else:
return "Error!"
if __name__ == '__main__':
sensor_value = "|".join([str(i) for i in range(10000000)])
print(run(sensor_value))
memory_profiler : Memory Profiling
Python은 머신러닝 같은 데이터 처리를 위한 언어로 자주 사용되기 때문에, 메모리 관련된 이슈에 자주 직면하게 된다.
따라서, 어느 부분이 memory를 많이 소모하는지 확인이 필요한 경우가 많다.
Python에서는 "memory_profiler"를 통해 memory 사용량을 측정할 수 있다.
[설치 방법]
설치 방법은 매우 간단하다. pip을 이용하여 설치한다.
pip install memory_profiler
[사용 방법]
사용 방법도 매우 간단하다. memory_profiler의 profiler을 import 하고, memory profiling을 하고자 하는 함수에 "@profiler" 데코레이터를 사용하고, 프로그램을 실행하면 끝난다.
[사용 예시]
from memory_profiler import profile
import numpy as np
@profile
def data_validation_check(sensor_value):
try:
for i in sensor_value.split("|"):
float(i)
return True
except:
print("Error")
return False
...
[결과]
결과는 다음과 같이, 테이블 형태로 터미널에 출력된다.
각 칼럼은 다음을 의미한다.
Line # : code 내 몇 번째 줄인 지
Mem Usage : 해당 라인이 실행되기 전의 메모리 사용량
Increment : 해당 라인의 실행으로 추가적으로 사용된 메모리의 양
Occurrences : 각 라인이 실행된 횟수
Line Contents : 라인 코드 내용
즉, memory profiler는 각 라인이 수행되기 전과 후를 스냅숏으로 메모리의 증분값을 보여주어, memory 사용량을 나타낸다. (따라서, memory를 해제하는 경우 등에는 음수값이 나올 수 있다.)
memory_profiler의 결과를 file 형태로 저장하기 위해서는, logger를 사용하거나, 아래와 같이 프로그램 수행 결과를 txt 형태로 내리도록 하면 된다.
python -m memory_profiler main.py > log.txt
memory_profiler를 run 한 후, 아래 명령어로 그래프를 그릴 수 있는데, 사실 이 그래프로 뭘 알 수 있는지는 의문이다. (그냥 시간에 따른 메모리 사용량만 표시된다.)
Line # Mem usage Increment Occurrences Line Contents ============================================================= 32 503.5 MiB 503.5 MiB 1 @profile 33 def data_sort(sensor_value): 34 579.9 MiB 76.3 MiB 1 return np.sort(sensor_value)
Filename: main.py
Line # Mem usage Increment Occurrences Line Contents ============================================================= 36 197.5 MiB 197.5 MiB 1 @profile 37 def data_cal_half_avg(sensor_value): 38 197.5 MiB 0.0 MiB 1 return np.mean(sensor_value[int(len(sensor_value) * 0.5):])
7499999.5 mprof: Sampling memory every 0.1s running new process running as a Python program...
사실, 언뜻 생각하기엔 sort에서 가장 많은 memory가 사용될 것이라고 생각했지만, 의외로 outlier 제거를 위한 순회나, split등에서 많이 사용된다는 것을 알 수 있다.
[주의점]
memory의 profile은 memory의 snapshot과 기록에 많은 추가 시간이 소요되기 때문에, memory profile과 실행시간 측정은 동시에 진행하면 안 된다.
memory가 snapshot 형태로 기록되기 때문에, memory 소요값이 절대적이지 않고, 실행 환경 등에 따라 다르다는 점을 꼭 기억하자!
Execution Time Profiling : line_profiler
Execution Time은 Python에서 가장 민감한 부분이기도 하다.
보통 time 모듈을 이용하여 디버깅을 진행하기도 하는데, 매구 간마다 디버깅을 위해 시간을 찍는 것도 매우 비효율적이다.
이런 비효율을 덜어줄 수 있는 Execution Time profiling 도구 line_profiler이다.
[설치 방법]
설치 방법은 memory_profiler처럼 pip을 이용하여 설치한다.
pip install line_profiler
[사용 방법]
사용 방법은 더 간단하다. 실행 시간을 측정하고 싶은 함수에 "@profile" 데코레이터를 넣어주고, 터미널에서 아래 명령어를 실행해 주면 된다.
kernprof -l -v main.py
[사용 예시]
# memory_profiler가 import 안되도록 한번 더 확인!
import numpy as np
@profile
def data_validation_check(sensor_value):
try:
for i in sensor_value.split("|"):
float(i)
return True
except:
print("Error")
return False
...
[결과]
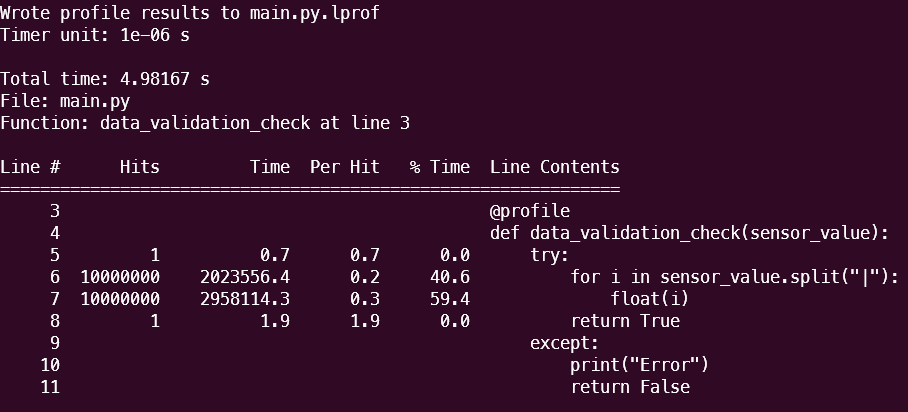
결과는 다음과 같이, 테이블 형태로 터미널에 출력된다.
우선 맨 위에, 시간 unit과 각 함수 total 수행 시간이 표시된다. (전체 total 수행 시간이 아니다.)
아래 각 칼럼은 다음을 의미한다.
Line # : code 내 몇 번째 줄인 지
Hits: 각 라인이 실행된 횟수
Time : 수행 시간
Per Hit: 각 실행당 걸린 시간
% Time : 함수 내 실행 시간에서 차지하는 퍼센트
Line Contents : 라인 코드 내용
line_profiler의 결과를 file 형태로 저장하기 위해서는, 아래 명령어를 사용하면 된다. line_profiler를 실행하면, 실행 파일에 대한 lprof의 파일 결과가 떨어지는데, 이를 text 파일로 떨구면 된다.
python -m line_profiler main.py.lprof > log.txt
[Sample 수행 결과]
첫 생각과는 다르게, validation check가 가장 많은 시간이 소요되는 것을 확인할 수 있다.
Timer unit: 1e-06 s
Total time: 4.83922 s File: main.py Function: data_validation_check at line 3
Line # Hits Time Per Hit % Time Line Contents ============================================================== 3 @profile 4 def data_validation_check(sensor_value): 5 1 0.5 0.5 0.0 try: 6 10000000 1970775.1 0.2 40.7 for i in sensor_value.split("|"): 7 10000000 2868439.0 0.3 59.3 float(i) 8 1 1.5 1.5 0.0 return True 9 except: 10 print("Error") 11 return False
Total time: 1.48381 s File: main.py Function: data_preprocessing at line 13
Line # Hits Time Per Hit % Time Line Contents ============================================================== 13 @profile 14 def data_preprocessing(sensor_value): 15 1 369882.5 369882.5 24.9 sensor_value = sensor_value.split("|") 16 1 1113930.3 1113930.3 75.1 sensor_value = list(map(float, sensor_value)) 17 18 1 1.3 1.3 0.0 return sensor_value
Total time: 2.66128 s File: main.py Function: outlier_remove at line 20
Line # Hits Time Per Hit % Time Line Contents ============================================================== 20 @profile 21 def outlier_remove(sensor_value): 22 1 337871.3 337871.3 12.7 data_mean = np.mean(sensor_value) 23 1 366792.1 366792.1 13.8 data_std = np.std(sensor_value) 24 25 1 5.7 5.7 0.0 lower_bound = data_mean - 3 * data_std 26 1 10.6 10.6 0.0 upper_bound = data_mean + 3 * data_std 27 28 1 1956595.8 1956595.8 73.5 sensor_value = [i for i in sensor_value if lower_bound < i and upper_bound > i] 29 1 0.7 0.7 0.0 return sensor_value
Total time: 0.415683 s File: main.py Function: data_sort at line 31
Line # Hits Time Per Hit % Time Line Contents ============================================================== 31 @profile 32 def data_sort(sensor_value): 33 1 415683.2 415683.2 100.0 return np.sort(sensor_value)
Total time: 0.003097 s File: main.py Function: data_cal_half_avg at line 35
Line # Hits Time Per Hit % Time Line Contents ============================================================== 35 @profile 36 def data_cal_half_avg(sensor_value): 37 1 3097.0 3097.0 100.0 return np.mean(sensor_value[int(len(sensor_value) * 0.5):])
[주의점]
memory profiler와 마찬가지로, line_profiler로 수행시간을 차분하여, 라인 별 수행시간을 구하는 것이다. 따라서, 절대적이지 않고 수행 환경에 따라 달라진다.
Process Profiling : py-spy
CPU는 운영체제의 스케줄링이나 프로세스 등에 따라 동적으로 변하기 때문에, 함수마다의 수행시간을 정확히 측정하는 것은 매우 어렵다.
따라서, CPU는 리눅스 명령어나 윈도 작업관리자를 통해, 프로그램 수행 후 observation 형태로 간접적으로 파악하는 방법 밖에 없다.
또한, CPU는 사용량이 많더라도, 조치하기가 매우 어렵다. 따라서, 너무 CPU 사용량이 많은 부분만 확인하는 정도의 이상감지용 지표로 활용하는 것이 좋다.
CPU 사용률을 직접 측정하기는 어렵지만, 각 Process에 걸리는 부하를 간접적으로 알 수 있는 도구가 있는데, 바로 py-spy이다.
[설치 방법]
설치 방법은 앞선 profiler들처럼 pip을 이용하여 설치한다.
pip install py-spi
[사용 방법]
사용 방법은 단순히 아래 명령어를 터미널에 입력해 주면 된다.
py-spy record -o profile.svg -- python main.py
[결과]
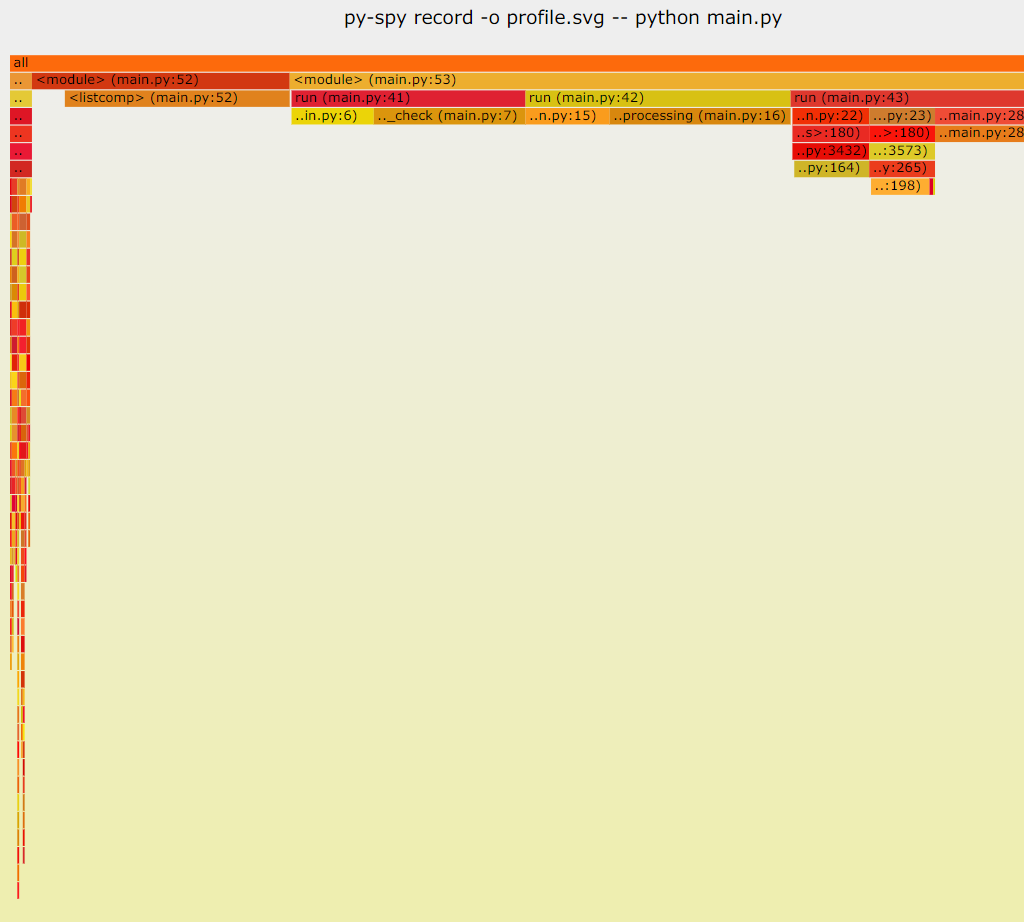
결과는 위에서 지정한 profile.svg(이름은 바꿔도 된다.) 파일의 스택 플레임 그래프 형태로 떨어진다.
결과는 다음의 형태를 가진다.
함수 호출 스택이 위에서부터 바깥쪽의 함수를 의미한다. 예를 들어, 예제의 run 함수 → data_preprocessing 함수 → split 함수 형태로 위부터 아래로 표시된다.
Box 표시 : 각 함수가 Box로 표시된다. Box의 크기가 해당 함수의 소비 시간을 나타낸다. 따라서, 상위 함수는 하위 여러 함수들의 박스들로 구성된다.
색상 : 어두운 색상에 있는 함수일수록 깊은 호출 스택을 의미한다.
일반적으로, 다음과 같은 결과 해석이 가능하다.
우선 Box가 큰 함수의 부분이 부하의 원인이 되는 경우가 많기 때문에 주목해서 봐야 한다.
Box가 큰 함수들 중, 호출 스택이 깊은 함수들은 여러 번 중첩되는 경우가 많은데, 이 부분의 중첩을 줄여야 개선이 가능하다.
다른 profiler들과 다르게, 내부의 import 된 함수 단위까지 표시가 되기 때문에, 어떤 구조로 함수가 호출되는지 이해가 쉽다.
[주의점]
사실, 수행 시간을 통해, 간접적으로 프로세스의 중첩이나, 부하를 확인하는 것이기 때문에, CPU 사용률과 직접적인 연관이 없다. (참고용으로만 사용하는 것이 좋다.)
이 밖에, Python 내장 profiler인 CProfile 같은 Profiler와, Palanteer, Pyinstrument 등의 Profiler 들도 존재한다. 하지만, 프로그램의 수행결과로 논문을 쓸 것이 아니라면, 다음과 같은 툴로도 충분하다고 생각한다.
H/W와 코드 환경, 연산하는 함수에 따라, 컴파일 및 최적화 정도는 천차만별이다. 따라서, 절댓값이 주목하기보다는 대략적으로 이런 효과가 있구나 정도로 생각해 주길 바란다.
import numpy as np
from numba import jit
import time
@jit
def numba_func(input):
sol = np.tanh(input)
return sol
def no_numba_func(input):
sol = np.tanh(input)
return sol
if __name__ == '__main__':
data_length = 1000000000
input_data = np.arange(data_length)
start_time = time.time()
numba_func(input_data)
end_time = time.time()
print("Elapsed Time (with numba):",end_time-start_time)
start_time = time.time()
no_numba_func(input_data)
end_time = time.time()
print("Elapsed Time (without numba):",end_time-start_time)
길이가 10억개의 데이터에 대해서 jit과 jit 옵션이 없는 코드를 실행해 보았다. jit을 사용한 것이 빠른 속도를 보여주는 것을 확인할 수 있다.
길이가 1억개의 데이터에 대해서 jit과 jit 옵션이 없는 코드를 실행해 보았다. jit을 사용하지 않은 것이 더 빠른 속도를 보여주는 것을 확인할 수 있다.
길이가 1000개 정도의 소규모(?) 데이터에서 실행 결과, jit의 overhead가 확실히 존재한다는 것을 확인할 수 있다.
→ 다만, JIT의 성능 향상에 대한 연산량은 H/W 등의 실험환경에 크게 영향을 받는다. 꼭, 실제 코드를 돌릴 환경에서 테스트해 보고 적용하는 것을 추천한다.
Numba 주의점
Numba는 대용량의 연산이 아닌, 소규모의 연산에서는 오히려 느린 성능을 보여준다. 이는 Numba의 JIT 컴파일에 약간의 오버헤드가 있기 때문이다.
Numba에서 성능 향상을 보기 위해서는, 최대한 간단하고, 배열 위주의 작업들을 대용량 데이터에서 사용해야한다. 제어 흐름이 복잡한 코드는 최적화에 한계가 있다.
nopython 옵션 적용 시, JIT이 컴파일 할 수 없는 경우에는 에러가 뜬다. Input과 Output의 타입, 함수 내의 연산이 명확한 경우에만 사용하도록 한다.
Numba가 효과있는 데이터 양등을 실제 프로그램이 돌아갈 환경에서 실험해 보고, 데이터 연산량을 대략적으로 계산하여, JIT을 적용한 함수와 적용하지 않는 함수를 각각 놓고 분기를 치는 것도 좋은 방법이다.
실제로 운영 단에 있는 코드 들에서는 하나의 함수에 복잡한 내용이 섞여있는 경우가 많다. 이러한 경우, numpy나 for문만 별도의 함수로 나눠서 JIT을 적용해줘야한다. 이러한 변경은 최적화에서는 이점이 있을지 모르지만, 가독성에서는 해가될 수 있다.
Numba는 Python의 고질 병인 속도 문제를 해결하기 위해, 등장한 라이브러리다. 비록, 대용량 데이터에서만 효과를 볼 수 있다는 아쉬운 점도 있지만, 이런 옵션이 존재한다는 것이 어딘가 싶다. (사실, 대용량 데이터가 아니면, 굳이 속도 문제가 치명적이진 않을 것이다.) 만약, 운영 환경에서 간혹 존재하는 대용량 데이터에 고통받고 있다면, 예외처리용으로 사용해도 좋을 것 같다.