GreaseLM 배경 설명
- GreaseLM은 2022년 Stanford에서 나온 ICLR 논문이다.
- 사실 KG에 대해, 전문적인 지식은 없지만, 최근 Language Model에 KG 정보 등을 이용해서 성능을 높이려는 방식이 많이 사용되고 있는 것 같아 흥미가 생긴다.
- 이 논문은 KG를 단순 LM의 학습을 도와주는 용도가 아니라, 두 modality 간의 정보를 섞는 fusion 개념으로 KG와 LM을 사용하였기에 굉장히 가치가 있는 논문이라고 생각한다.
Abstract
- 복잡한 텍스트 내러티브 질문에 대답하기 위해서는 Context와 그 안에 숨겨진 지식들 모두에 대한 추론이 필요하다.
- 현재(그 당시) QA 시스템들에 많이 사용되는 pretrained Language Model(LM)은 concept 들 간의 관계를 robust 하게 표현해주지 못한다.
- Knowledge Graph(KG)은 구조화된(관계에 대한) representation들을 가지고 있기 때문에, LM과 함께 사용되곤 한다.
- 하지만, KG representations들과 language context 정보들을 어떻게 효과적으로 융합할 수 있는지에 대해서는 미지수이다.
- 이 논문에서는 GreaseLM이라는 LM에서 추출된 representations(laguage context 정보)와 GNN의 정보들(KG 그래프 정보)을 융합해서 사용하는 새로운 모델을 제시한다.
- 이 모델에서는 각 modal 들이 다른 modal에게 정보들을 전달하는 구조로 정보를 융합한다.
Introduction
[Language Model]
- QA task에서는 textual context 정보뿐 아니라, 세상에 대한 지식(박학다식을 이렇게 표현해 놓았다.)이 필요하다.
- 최근에는 (그 당시) large pretrained LM을 QA 분야에 사용하는 것이 주류가 되었다. pretrained LM의 경우에는 pre-training 과정에서 수많은 text 데이터들을 학습하기 때문에, 그 과정에서 텍스트들에 함축된 knowledge 들을 학습하게 된다.
- 이러한 pretrained LM 모델들은 좋은 성능을 보이지만, fine-tuning 단계에서 학습한 데이터와 다른 유형의 문제를 풀 때는 어려움을 겪는다.
- 그것은 이러한 모델들이 Question과 Answer 사이에 pattern에 의존하지, 그 사이의 reasoning에는 많이 의존하지 않기 때문이다. 이러한 reasoning은 context 데이터와 implicit external knowledge가 합쳐진 정보이다.
[Knowledge Graph]
- 기존의 연구들중 KG를 도입해서 구조화된 reasoning과 query answering에 효과를 본 연구들이 있다.
- 하지만, text 문장으로 구성된 question & answer와 KG의 knowledge를 어떻게 결합할 것인지에 대해서는 아직 정답이 없다.
- 좋은 reasoning을 위해, 두 modal 정보를 함께 사용하기 위한 연구들이 있었다. 하지만, 그 연구들은 얕고 non-interactive 한 방식(각 modal의 정보를 각각 encoding 하고 prediction 결과를 섞거나, 한 modal의 정보를 활용하기 위해 다른 modal을 사용하는 방식)을 사용하였다.
- 결과적으로, 이러한 방법들은 두 modal 간의 유용한 정보들을 어떻게 섞을 것인지에 대한 방법을 고민하게 하였다.
[Grease LM]
- 이 논문에서는 GreaseLM이라는 LM과 KG가 여러 layer에 거쳐서 정보를 fusion하고 exchange 할 수 있는 새로운 구조를 제안한다.
- GreaseLM은 context를 처리하는 LM과 KG를 처리하는 GNN으로 구성된다. 각각 LM와 GNN Layer를 거친 후, 각 modality끼리 정보를 교환할 수 있는 bidirectional interactive schema를 통해, interaction representation을 담게 된다.
- 이를 위해, LM을 위한 Interaction Token과 GNN을 위한 Interaction Node를 사용한다.
- GreaseLM은 다른 LM 구조에 비해 QA에서 좋은 성능을 보인다. (기존에 KG를 같이 사용하던 모델도 포함해서)
- 특히, GreaseLM은 효과적인 Reasoning이 필요한 질문들에서 매우 좋은 성능을 보인다.
Related Work
- KG 정보를 사용하는 것은 QA 분야에서 각광받고 있다.
- 몇몇 연구들은 text 처리를 위한 LM과 knowledge 처리를 위한 graph를 사용해서 정보를 융합하는 방법을 사용한다.
- 다른 연구들은 한 KG 정보를 text 데이터를 활용하는데 도움을 주는 용도로 사용한다. (KG를 활용한 QA example Augmentation 등)
- 반대로 text 데이터를 활용하여 KG를 뽑아내는 데 사용하는 연구들도 있다.
→ 정리하자면, 기존에도 KG와 text 데이터를 같이 사용하는 연구들은 많았으나, 한 modal의 데이터를 다른 modal에 간접적으로 사용하는 등, 효과적으로 두 정보를 결합하지 못했다.
- 최근에는 두 modality들의 정보의 deeper integration을 위한 방법들이 연구되고 있다.
- 어떤 연구는 LM이 implicit knowledge(Embedding을 의미하는 것 같다.)을 만드는 것을 학습하기 위해, KG를 사용한다. 하지만, 이 방법은 LM을 학습할 때를 제외하고는 KG 정보를 사용하지 않기 때문에 reasoning을 guide 할 수 있는 중요한 정보를 사용하지 못한다. (실제 KG 정보를 사용하지는 않는다.)
- 더 최근에는, QA-GNN이라는 모델이 LM과 GNN이 message passing을 통해, 같이 학습하는 방법을 제안하였다. 하지만, 이 논문에서는 LM의 textual component를 표현하는데 single pooled representation을 이용하여, text representation에 대한 update에 한계가 있다.
- 기존 방법들과 다르게, 이 논문에서는 LM의 각 token representations들과 GNN의 여러 layer들의 정보가 섞일 수 있어, 각 modality에서 다른 modality의 정보를 반영할 수 있다.
- 동시에 각 modality들의 구조를 유지하여 함께 사용한다.
→ 정리하자면, 그래도 최근에는 LM과 QA의 정보를 효율적으로 사용하는 구조를 제안해 보았지만, 아직은 제한적으로 사용되고 있다. 이 논문에서는 text 내의 token과 실제 KG의 연결 정보가 잘 결합될 수 있는 구조를 제안한다.
- 어떤 연구들은 KG와 LM을 pretraining 단계에서 같이 활용하기도 한다.
- 하지만, QA에서와 비슷하게 multiple layer들에서의 interaction을 고려한 것이 아닌, knodwledge를 language에 이용하는 형식으로 사용된다.
GreassLM
- 이 논문에서는 lareg-scale LM을 KG를 이용한 grpah reasoning 모듈로 augment 하였다.
- GreaseLM은 2개의 component들로 구성되어 있다. 1) unimodal LM layers: input token(text 데이터)으로만 학습함 2) upper cross-modal GreaseLM layers: lanugage sequence들과 linked KG로 학습되어, 두 modality의 정보를 함께 사용할 수 있음. 논문에서는 LM layer들을 N개, GreaseLM layer를 M개 사용해서, 총 N+M개로 이뤄진다고 말하고 있다.
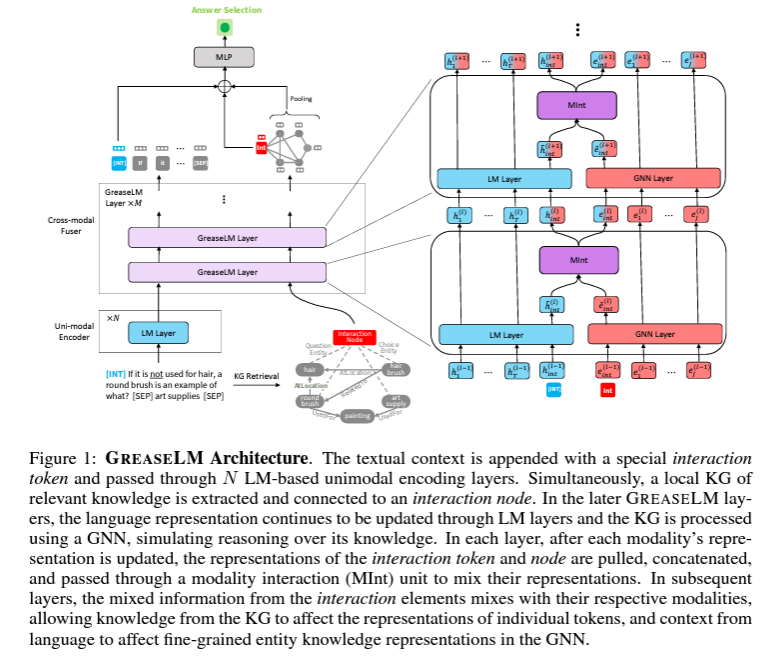
- Notation : multiple choice question answering에서 context paragraph는 c, question은 q, candidate answer set은 A이고, 모두 text로 구성되어 있다. 이 논문에서는 external knowledge graph(KG)를 G로 정의하여 content에 대한 background knowledge를 제공하는 데 사용한다. QA 문제는 c, q, A, G가 있을 때, A에 속하는 a를 찾는 것이 목표이다. 일반성을 위해, 본 논문에서는 정답을 a로, natural language의 sequence의 각 token을 w로 1부터 T까지 나타낸다. KG의 각 노드는 e로 1부터 J까지 나타낸다.
- Input Representation
- 우선 context와 question, answer를 separator token 등을 이용해서 concatenate 한다.(BERT에서 사용하던 방법이다.) 이 token을 tokenize 해서 combined sequence를 구성한다. {w1,..., wT}
- Input sequence를 KG에서 subgraph(현재 Question과 관련 있는 정보를 제공)를 뽑는 데 사용한다. subgraph는 {ㄷe1,..., eJ}
- KG Retrieval : QA context가 있을 때, subgraph를 뽑기 위해 기존 다른 논문(QA-GNN: 나중에 읽어봐야겠다.)의 방법을 사용한다. subgraph의 각 Node는 context, question, answer와 연결되어 있는지 또는 해당 Node의 이웃으로 연결되었는지에 따라 유형이 할당된다.
- Interaction Bottlenecks : cross-modal GreaseLM layers에서 두 modality들 간의 정보가 섞인다. 이를 위해 special interaction token을 사용하는데, 이것을 w_int로, special interaction node를 e_int로 정의한다.
- Language Pre-Encoding
- unimodal encoding component에는 token과 segment와 positional embeddins들을 합해서 input으로 사용하여, LM layer에 통과시킨다. l번째 layer를 거친 pretrained representations들은 아래와 같이 정의된다. LM-Layer들의 parameter들은 pretrained model을 사용하여 이미 학습되어 있는 상태이다.
- 앞서 언급한 대로, LM-layer의 총개수는 N개이다.
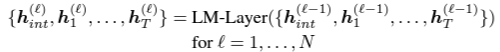
- GreaseLM
- GreaseLM은 cross-modal fusion component를 사용한다.
- GreaseLM layer는 각 정보를 독립적으로 encode 하고, 그 정보들을 spectial token과 node의 bottleneck을 통해서 fuse 한다.
- 3가지 component로 구성되어 있다.
- transformer LM encoder block : language context를 encoding 함.
- GNN layer : KG entitie들과 relation들의 정보를 담음
- modality interaction layer : interaction token과 interaction node 간 정보를 교환함.
[Language Representation]
- l번째 GreaseLM layer의 feature는 Language Pre-Encoding 된 representations에 추가적으로 l번의 transformer LM encoder를 거친 정보이다.
- GreaseLM Layer의 l번째 embeddings는 다음과 같이 나타난다.
- 뒤에서 추가적으로 언급하겠지만, h_int는 KG의 representation을 encode 하는 역할을 한다.
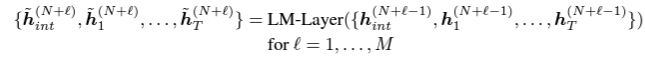
[Graph Representation]
- GreaseLm layer는 QA example과 관련된 local KG 정보도 함께 encoding 한다.
- Graph를 뽑기 위해, 처음으로 initial node embeddings를 pretraned KG embeddings를 통해 뽑는다. 이때, iteraction node, e_int의 initial embedding은 random 하게 초기화된다.
- 그러고 나서, GNN의 각 layer는 현재 node embeddings들을 입력으로 받아, information propagation을 수행하고, 이를 통해 fuse 된 node embedding을 생성한다.
- 이때, 사용되는 GNN은 QA-GNN에서 사용된 방법을 따른다.

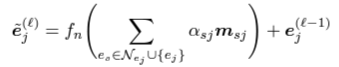
N: e_j의 neighborhood, m_sj:e_s가 e_j에게 보내는 message, a_sj:message에 대한 attention, f_n: 2 layer MLP
- Entity들 간 message는 relation과 node type을 이용해 다음과 같이 정의된다.
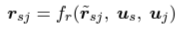
f_r : 2 layer MLP, r_hat_sj: relation embedding, u_s, u_j : node type embedding

- message를 어느 비중으로 보낼 것인지, 결정하는 a_sj는 다음과 같이 결정된다.
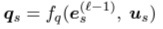

f_q, g_k : linear transformation
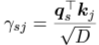

→ 해석하자면, GreaseLM의 node representation은 전 단계 layer의 node들과 attention을 적용한 neigbor node들이 보낸 message들의 합으로 나타난다.
이때, message는 1) enitity들의 node type embedding과 relation embedding을 이용한 MLP output과, 2) neiborhood의 node type embedding에 두 entity 간 relation representations, 3) neighborhood의 l-1번째 LM embedding representation을 linear transformation 한 값으로 구해지고,
message는 query(neighborhood의 l-1번째 LM embedding representation과 그의 node type embedding의 linear transformations)와 key(현 entity의 l-1번째 LM embedding representation과 그의 node type embedding과 neighborhood 간의 relation을 linear transformation)한 값으로 구해진다.
이때, 두 사이의 relation 값의 비중은 q와 k의 곱으로 구해지고(consine similarity 같은 개념인가 보다.) 이것을 neighborhood 간 normalization을 통해 0~1 사이의 가중치를 구한다.
(자세한 내용은 QA-GNN을 참고하는 편이 좋아 보인다. 그래도 천천히 읽다 보면 어떤 걸 의도하는 이해가 간다.)
[Modality Interaction]
- LM과 GNN이 각각 정볼르 embedding 한 이후에, modality interaction layer(MInt)를 통해 두 modality들의 정보가 interaction token과 interaction node 간의 bottleneck을 통해 섞이길 바란다.
- 이때, l번째 MInt에서는 interaction node의 embedding과 interaction token의 embedding을 concate 한 값을 Input으로 받아서 처리하고, output은 그 결과를 split 해서 각각 가져간다.
- MInt로는 2 layer MLP를 사용한다. interaction token과 interaction node를 제외한 다른 token 및 node들은 이 단계에서 사용되지 않는다. 하지만, 직접적으로 MInt의 Input으로 사용되지는 않더라도, interaction node와 interatction token에는 각각 다른 token 및 node의 정보가 담겨있다. (interaction node는 relation을 통해, 다른 entitiy들의 영향을 포함하고, interaction token은 transformer의 encoding 단계 중, 다른 token 정보를 포함하기 때문에 그런 것이다. 이 부분에서 아이디어가 매우 좋다는 생각이 들었다.)
Experiments
- CommonsenseQA와 OpenBook QA에서 기존 모델들 (LM only or LM + KG) 보다 좋은 성능을 보여준다.
Conclusion
- 이 논문에서는 GreaseLM이라는 knowledge graph와 language model 간의 정보를 교환할 수 있는 새로운 구조를 제안했다.
- 실험결과는 기존의 KG+LM의 구조나 LM 단독으로 사용된 것들에 비해 좋은 성능을 보여준다.
- 특히, 뉘앙스 등의 reasoning이 포함된 문제에서 더욱 효과적이다.
출처
총평
평소 word embedding을 보면서, 저절로 만들어지는 KG 아니야? 하는 생각을 가지고 있었다. 그만큼 KG와 LM은 비슷한 구조이면서, 서로를 보완해 줄 수 있는 데이터인 것 같다. 사실 두 정보를 함께 사용하는 논문이 이미 많이 나왔을 줄 알았는데, 그만큼 매우 어려운 것 같기도 하고, 역시 transformer의 위대함이 아닌가 싶다.



