반응형
GPT-2 배경 설명
- GPT-2는 OpenAI에서 2019년 발표한 논문이다.
- GPT-2는 기존의 대규모 LM 구조인 GPT-1의 구조를 따르지만, 학습을 Unsupervised Multitask Learning을 사용하여, 범용성 있는 자연어처리를 할 수 있는 모델을 제시했다.
- 또한, parameter의 크기와 성능이 log-linear한 상관관계가 있다는 것을 제시하여, 많은 각광을 받았다.
Abstract
- 자연어 처리의 다양한 분야에서 task specific한 데이터셋으로 spervised learning 하는 것이 일반적이다.
- 이 논문에서는 학습과정에 task specific한 지도학습 없이 학습하는 언어모델을 제안한다.
- 주어진 문서와 질문에 대한 정답을 구하는 문제에서, training dataset 없이 4개의 베이스라인 시스템 중, 3개와 맞먹거나, 그를 능가하는 수준을 기록했다.
- LM의 용량은 zero-shot task transfer를 성공적으로 하는데, 중요한 요소이다. 또한, 용량 증가에 따라, 성능도 log linear 하게 증가한다.
- GPT-2는 1.5B paramerter의 Transformer로 이뤄져있고, 8개의 zero-shot 환경의 language modeling 데이터 중, 7개에서 가장 좋은 성능을 보여준다.
Introduction
- Machine Learning 시스템들은 large datasets와 high-capacity model들을 사용하여 supervised learning을 사용하여 뛰어난 성능을 보인다.
- 그러나, 이러한 시스템들은 다루기 힘들고, 데이터 분포나 task 변화에 따라 민감하다.
- 현재(그 당시) 시스템들은 generalist라기 보다는, 좁은 분야의 전문가의 특성이 있다.(task specific에 특화되어 있다는 뜻) 이 논문에서는, 다양한 분야에서 사용할 수 있는 general system으르 만들고자 한다.
- 저자들은 single domain dataset으로 single task tranining을 진행하는 것이, 현재(그 당시) 시스템이 generalization을 잘 못하는 이유라고 생각한다.
- robust sytstems을 만들기 위해, training과 test에서 다양한 domain과 task의 데이터셋을 사용해야한다. 최근(당시)에는 몇몇 benchmarks 등이 등장했다.(GLUE, decaNLP)
- Multitask learning은 general performance를 향상시키기에 좋은 방법이지만, NLP에서는 초기 단계이다.
- 한편, LM 분야에서는 pre-training과 supervised fine-tuning을 결합하는 방식을 주로 사용한다. (GPT-1, BERT 등등)
- 이 논문에서는 LM의 down-stream 단에서도 zero-shot learning으로 학습할 수 있는 새로운 모델을 소개한다. 이 새로운 LM은 zero-shot setting에서도 좋은 성능을 보인다.
Approach
- GPT-2에서도 일반적인 Language Modeling을 사용한다.
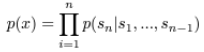
- 일반적인 signle task에서 conditional dsitribution은 p(output|input)이다.
- general system에서는 다양한 task들을 처리해야하기 때문에, conditional diestribution은 p(output|input, task)이다.
- task conditioning은 종종 architectural level에서 실행되기도 하고(task specific encoder & decoder), algorithmic level에서 수행되기도 한다. 어떤 연구에서는 language가 어떤 task를 수행할지를 지정해주기도 한다.
- 언어 모델링은 symbol을 예측하는 supervision 방식으로 학습하지 않아도, 학습 가능하다. supervised objective의 최솟값과 unsupervised objective이 최솟값이 동일하기 때문에, 같게 수렴하기 때문이다. unsupervised learning은 속도는 느리지만, supervised learning과 같게 optimize 될 수 있다.
[Training Dataset]
- 기존 LM의 학습에는 single domain의 text(뉴스 기사 등)가 사용되었다.
- 이 논문에서는 크고 다양한 데이터셋을 수집하여, 다양한 task와 context를 커버할 수 있도록 데이터 셋을 다양화하였다.
- 다양하고, 풍부한 text를 수집하는 가장 좋은 방법은 Common Crawl 같은 곳에서 web scrape을 진행하는 것이다. 하지만, 기존 LM 데이터셋보다 양이 많음에도 불구하고, 데이터의 quality 이슈가 있다.
- 어떤 방법들에서는 Common Crawl에서 small subsample만을 이용해서 좋은 성능을 보였다. 하지만, 이 방법은 특정 task의 성능을 향상 시켜주지만, 이 논문에서는 어떤 task 등 커버할 수 있도록 학습을 진행할 수 있는 데이터셋을 수집하고자 했다. (특정 분야만 수집하면, task specific이 한정되기 때문에)
- 이를 위해, 이 논문에서는 document quality를 강조하는 새로운 web scrape을 만들었다. 새로운 web scrape은 인간에 의해 filtered된 문서만 수집한다.
- Reddit에서 3 karma(안써봐서 모르겠지만, 좋아요 같은 것 인가보다.) 이상을 받은 데이터만 수집하여, manual filtering 하였다.
- 결론적으로 만들어진, WebText 데이터셋은 45 million개의 링크를 포함한다. HTML에서 text를 뽑기 위해, Dragnet과 Newspaper content extractor들을 사용하였다.
[Input Representation]
- charactre와 word level의 중간을 사용하는 Byte Pair Encoding을 사용하였다.
- 이러한 방식은 word-level LM의 성능과 byte-level 방법의 generality의 장점을 결합할 수 있다.
[Model]
- 이 논문에서는 LM의 base architecture로 Transformer를 사용했다. GPT-1 모델을 약간의 변화를 제외하고 그대로 사용하였다.
- Layer normalization은 각 sub-block의 input으로 이동하였고, final self-atteention block 이후에 추가 layer normalization을 더했다.
- Vocuibulary는 50257개로 증가시켰고, context size는 최대 1024개까지 사용하였다.
Experiments
- 기존 모델들과의 비교를 위해서 4개의 LM의 space size에 따라 이 모델의 성능을 log-uniformly하게 계산해서, 성능을 구했다.
- 가장 작은 건 GPT-1과 parameter 정도의 크기이고, 2번째로 작은 것은 BERT 사이즈의 parameter를 가지고 있다.
Language Modeling
- 이 논문에서는 BPE를 사용하기 때문에, tokenization 같은 pre-processing이 필요하지 않다.
- WebText LM dataset을 이용하여, log-probabilty를 이용하여 학습한다.
- <UNK>은 WebText에서 거의 나타나지 않는다. (40 billion bytes 중 26회만 등장)
- Zero-Shot으로 수행된 모델들 간의 비교에서, LM 분야의 8개 task 중 7개에서 SOTA를 달성하였다.
- Children's Book Test, LAMBADA 데이터셋에서 좋은 성능을 보였다.
- Summarization과 QA, Translation에서는 좋은 성능을 보이지 못하였다.
Conclusion
- 이 논문에서는 충분하고 다양한 데이터셋으로 학습된 large language mode이 많은 domain들과 dataset들에서 사용될 수 있음을 보여주었다.
- GPT-2는 zero-shot으로 학습된 모델 들중, 8개의 testset 중 7개에서 SOTA 성능을 보여주었다.
Reference
OpenAI. (2019). Improving Language Understanding by Generative Pre-Training. Retrieved from https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
총평
이 논문에서는 사실, 새로운 구조의 모델이나 학습방법을 제시하는 기존 LM 분야의 논문들과 달리, Unsupervised Learning으로 Language Model을 학습해 보았다는 데에 있다. 이 과정에서 학습 과정에 Parameter의 양과 성능의 연관성을 언급하여, 추후에 LM 분야의 구조들이 크기를 더욱 늘리는 데 기여했다고 생각한다.



