반응형
논문 배경 설명
- Fine-tuning Image Transformers using Learnable Memory은 2022년 CVPR에 제출된 Google 논문이다.
- memory token 개념을 사용하여, ViT에서 과거 task에 대한 정보를 저장하여, 성능을 유지하고, 새로운 task에 대한 학습을 진행할 수 있는 방법을 소개했다.
- 저자들은 지속 & 확장 가능한 memory 개념으로 소개하는데, 만약 진짜라면, external memory 개념으로 탈부착 가능한 memory가 될 수도 있지 않을까? 하는 생각이 든다.
Abstract
- 이 논문에서는 Vision Transformer model에 학습 가능한 memory token을 넣은 새로운 ViT 모델을 소개한다.
- 이 모델의 방법에서는 하나의 task에서 학습한 parameter들을 새로운 task 학습에서 활용 가능하다.
- 이를 위해, 각 layer들에 특정 dataset에 대한 contextual 정보를 제공하는 "memory token"이라는 learnable embedding vector들을 도입하였다.
- 이러한 간단한 변형은 transfer learning에서 단순 head만을 fine-tuning 하는 것보다 큰 성능 향상을 보이고, 연산 비용이 매우 큰 full fine-tuning에 비교해서도 약간의 성능 차이만 보인다. (약간 낮다.)
- 또한, 이 논문에서는 computation 재사용으로 새로운 downstream task들에 사용가능한 attention-masking 방법을 소개한다.
Introduction
[배경]
- ViT 모델은 일반적으로 대량의 데이터들을 통해 학습되고, 다양한 downstream task에서 성능 향상을 위해 fine-tuning 하는 방법을 사용한다.
- 높은 정확도를 위해, 전체 모델을 목적에 맞는 task에 fine-tuning하는 것이 가장 좋은 방법이다.
[문제]
- 하지만, 일반적으로 Transformer 기반 모델들은 많은 수의 parameter로 구성되어 있기 때문에, fine-tuning 과정에 연산 cost가 크고, 특히, 전체 모델 fine-tuning 방법은 learning rate에 민감하다는 문제가 있다.
[소개]
- 이 논문에서는 transformer의 각 layer에 learnable token을 새로 추가하여, pre-trained model을 구성하는 새로운 방법을 소개한다.
- 새로운 token들은 최종 prediction 성능 향상에 사용될 수 있는 contextual 정보들을 포함한 영구적 memory처럼 동작한다.
- 또한, 이러한 token은 pixel 기반 patch부터 최종 concept 수준까지 다양한 수준의 추상화 개념을 나타낼 수 있다. (pixel 정보부터 다양한 문맥 정보까지 모두 포함할 수 있다.)
[결과]
- 새로운 방법은 downstream task에서 기존 head를 fine-tuning한 모델보다, 큰 성능 향상을 보였다.
- 또한, 이러한 아키텍처 디자인은 약간의 computing cost 증가만으로, 새로운 taksk를 학습하면서도, 기존 task에 대한 성능을 유지할 수 있게 한다. (기존 모델들은 새로운 task를 학습하면, 이전 task에 대한 성능이 떨어짐)
- 이를 위해, 적절한 attention masking이라는 새로운 방법을 소개하여, 과거 task에 대한 정보를 memory에 저장하는 방식을 사용한다. 이러한 방식은 continual learning의 개념처럼, 계속하여 새로운 기능을 더하여 다양한 task에 모두 활용 가능한 하나의 모델로 활용될 수 있다.
Memory Model
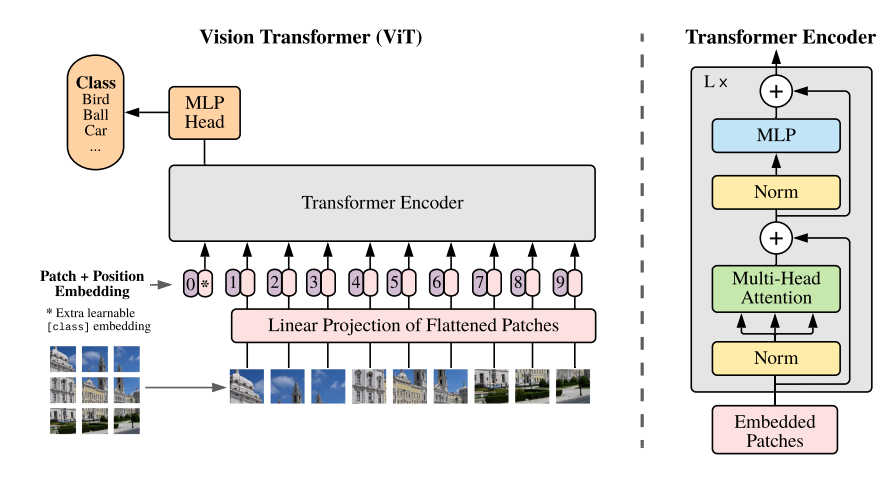
- Base mode로는 original ViT 논문의 구조를 그대로 사용한다. (다만, 이 논문에서는 classification model들만을 고려하기 때문에, decoder는 사용하지 않는다. )
- 일반적인 image transformer의 input은 다음과 같다. (Epos : positional embedding, Xcls : class token)
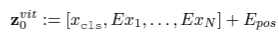
- 논문에서는 새로운 memory 정보를 더하기 위해, 이 input에 m개의 learning embedding(Emem)을 concatenate해준다.

- 즉, N+1+m token이 Transformer encoder layer들의 input으로 사용된다.
- 각 layer들은 일반 ViT의 layer들과 거의 비슷하다. 유일하게 다른 점은 self attention module의 처음 N+1 token들만 output으로 보낸다는 점이다. (m개의 token들은 다음 layer로 보내지 않음)
- 따라서, l번 layer의 output은 N+1개의 token을 가진 y_l로 명명하면, 연속적인 layer들은 모두 아래와 같은 pattern의 input을 받는다. (전 layer에서 token N+1개와 memory token m개)
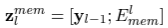
- 전체 network 구조는 아래와 같다.

[Fine-tuning with full attention]
- 이 모델에서 memory의 주된 용도는 fine-tuning에서의 활용이다.
- 이를 위해, randomly-initialized memory token을 제시하고, gradient descent를 활용하여 memory token을 학습한다.
- 이 방법은 좋은 결과를 보여주지만, 이렇게 학습된 model은 hidden activation들의 변화가 일어나, 과거 task에 더 이상 활용 불가능하다.
[Attention masking for computation reuse]
- 새로운 task만을 위한 fine-tuning에서는 문제가 되지 않지만, 앞선 task의 성능을 유지하면서, 새로운 task를 학습하고 싶은 경우에는 활용 불가능하다.
- 이 논문에서는 기존 dataset class token을 유지하면서, 새로운 dataset class token에 대한 memory 구조를 사용한다.
- 결과적으로, parameter들과 computation을 reuse 하여 동일 input에 대한 multiple task들을 처리할 수 있다.
- 이를 위해, original class token 및 input patch들이 새로운 dataset이 사용하는 memory token 및 new class token에 활용되지 않도록 막는 attention mask를 사용한다. (attention mask의 동작은 아래와 같다. 아래 그림처럼, 해당하는 학습에 대한 class token만 유지하고, 다른 class들은 masking 한다. 별표가 mask)
- 각 task의 head는 각 dataset token에 연결된다.

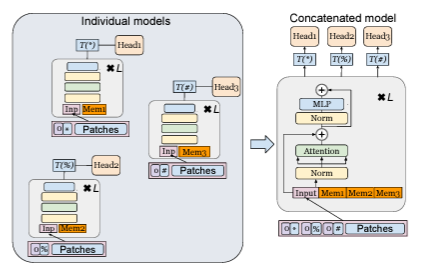
[model concatenation]
- Attention masking은 새로운 task 확장을 위한 memory 추가에 이용될 수 있다.
- 새로운 dataset에 대한 model 학습 시에는 attention masking을 이용하여 이전 dataset들에 대한 참조를 막고, 새로운 dataset에 대해 학습하는 방법을 사용한다.
- 아래 그림처럼, 각기 독립적으로 학습된 memory를 연결하여, 모델을 구성한다.
Experiments
[실험 setup]
- ViT-B/32 base transformer model을 base 모델로 사용하였고, ViT original paper에서 제공된 Imagenet-21K pretrained model을 사용했다. (80M parameters)
- orginal ViT의 fine-tuning 방법을 따라, cosine learning reate schedule 등의 fine-tuning setup을 그대로 사용했다.
- batch size는 512이고, 20000 step의 fine-tuning을 진행했다.
- SGD를 사용했고, gradient clipping을 사용했다. 5-step의 linear rate warmup도 했다.
- Memory는 N(0,0.02)로 initialization 시켰다.
- 성능 측정을 위한 dataset으로는 CIFAR-100, i-Naturalist, Places-365, SUN-397을 사용했다.
[실험 모델: Baseline fine-tuning]
Full fine-tuning
- 전체 model을 fine-tuning 함. 가장 expensive 하고, 각 task가 전체 model이 필요하기 때문에, 실용성이 가장 떨어짐. overfitting 가능성이나, learning rate에 민감함.
Head-only fine-tuning
- classifier의 head만 fine-tuning 함. 이 방식은 pre-trained의 mmbedding을 재활용함. 가장 큰 장점은 parameter들과 compute를 재사용할 수 있다는 것.
Head + Class token
- head와 class token을 fine-tuning함. 이 방식에서는 input token attention이 새로운 class token에 따라 바뀌면서, 연산 재사용이 불가능함.
[실험 모델: memory fine-tuning]
Memory + head + class token
- memory fine-tuning 모델로 부르는, 논문에서 소개된 모델임. 1,2,5,10,20 cell에 대한 실험을 진행함. 각 layer에서 20개 이상에서는 더 이상 성능 향상이 일어나지 않음. cell 5개가 알맞았음.
Memory with attention mask
- head-only fine-tuning과 Head + Class token의 장점을 결합한 방법. Head + Class token보다 높은 성능을 보이고, full-attention fine-tuning보다는 약간 낮은 성능을 보임. 이 방법의 가장 큰 장점은 독립적으로 다양한 task를 fine-tuning 할 수 있다는 것이고, 여러 연산을 하나의 모델로 모을 수 있다는 것.

[Transfer Learning 성능 비교]
- full fine-tuning은 learning rate에 민감하다. large learning tate에서 큰 성능 저하를 일으켜, 이 부분에서는 memory와 head-only fine-tuning이 오히려 더 좋은 성능을 보인다.
- 아래 그림에서 확인할 수 있듯, memory를 이용한 방법들이 다른 방식의 fine-tuning보다 좋은 성능을 보인다.
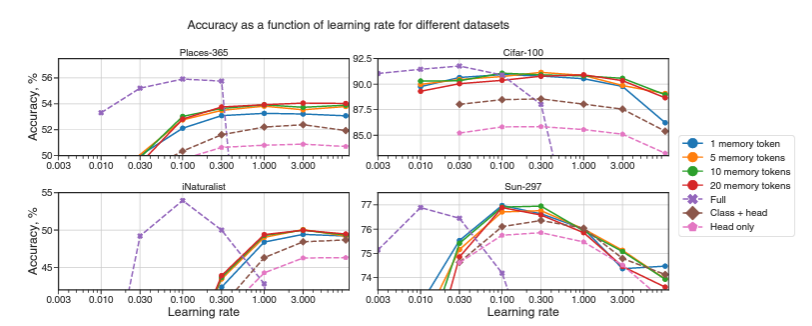
- 각 fine-tuning의 가장 optimal learning rate에서의 성능을 비교해 보았을 때, 결과는 아래 표와 같다.
- 많은 데이터셋에서 5~20 cell 사이의 memory fine-tuning이 좋은 성능을 보인다.

Conclusion & Limitation
- 이 논문에서는 memory 구조를 transformer model에 결합한 새로운 방법을 제안했다.
- memory를 사용한 새로운 모델은 fine-tuning에서 좋은 성능을 보였고, 다양한 task 학습을 가능하게 했다.
- memory yoken은 attention model의 중요한 부분으로, lifetime and continuous learning에 중요한 요소가 될 것으로 생각된다.
- 몇 가지 한계와 future work를 소개한다.
[scaling memory]
- 저자들은 memory token이 특정 숫자를 넘어가면, 성능 향상이 줄어드는 것을 발견했다.
- 한 가지 가능한 방법은 Top-K memory token만 참조하도록 제한을 거는 것이다. 이러한 방법은 불필요한 token들의 참조를 막아, background noise 등을 제거할 수 있을 것이다.
[combining episodic memory with learnable memory]
- Episodic memory와 함께 사용하는 방법도 생각해 볼 수 있다.
[incremetal model extension]
- 논문에서는 multiple attention masking model이 독립적으로 학습되어 하나의 모델로 합쳐지는 방법을 사용하였다. 하지만, 순차적인 학습으로 인한 중간 메모리 축적으로 생기는 이점(아마, 각기 다른 학습 간의 시너지를 의미하는 것 같음)은 커리큘럼 학습에 중요하고, 이것이 향후 연구의 주제가 될 것이다.
논문 총평
- 매우 아이디어가 간단하고, 아이디어에 대한 실험 결과가 매우 명확한 논문이다.
- 과거에 Knowledge distilliation을 잠시 파본 기억이 있는데, CNN 기반에서 distillation이 매우 어렵다고 생각했었는데, ViT 기반에서 memory token 개념을 사용하여 해결한 것이 매우 인상적이다. (그 후론 CNN 기반에서 방법을 찾아본 적이 없어서, 비슷한 아이디어가 있는지는 모르겠다.)
- 다만, 실제 데이터에서 잘 working 하는지는 직접 실험을 해봐야 판단이 가능할 것 같다.
Reference
Sandler, M., Zhmoginov, A., Vladymyrov, M., & Jackson, A. (2022). Fine-tuning image transformers using learnable memory. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12155-12164).
'Computer Vision' 카테고리의 다른 글
| EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention 논문 리뷰 (1) | 2024.12.30 |
|---|---|
| MobileViT v2 논문 리뷰 (34) | 2024.01.08 |
| MobileViT 논문 리뷰 (57) | 2023.12.07 |
| DETR : End-to-End Object Detection with Transformers 논문 리뷰 (47) | 2023.11.07 |
| DeepVit: Towards Deeper Vision Transformer 논문 리뷰 (1) | 2023.10.11 |