반응형
DeepViT 배경 설명
- DeepVit는 2021년에 ViT에 후속으로 나온 논문이다.
- ViT의 등장 이후, CNN 처럼 ViT를 깊게 쌓기 위한 방법을 제시한 논문으로, ImageNet classification에서 기존 CNN 기반의 SOTA를 넘어서는 성능을 보였다고 한다.
Abstract
- 이 논문에서는 Image Classification에서 Layer가 깊어질수록 좋은 성능을 내는 CNN과 달리, ViT의 performance는 layer가 깊어질수록 성능이 더 빨리 saturate 되는 것을 발견했다.
- 이것은 transformer의 사이즈가 커지면서, attention map들이 점점 비슷한 형태를 띠는 "attention collapse issue" 때문이다.
- 이것은 ViT에 deeper layer들을 적용하기 위해서 self-attention 방식이 효과적이지 못함을 보여준다.
- 이러한 결과로, 이 논문에서는 간단하면서 효과적인 "Re-attention"이라는 attention map을 재생성해서, layer들의 다양성을 향상하는 방법을 제안한다.
- 이 방법은 기존 ViT를 조금만 수정하더라도 좋은 성능을 보인다.
Introduction
[배경]
- CNN 방식은 Image Classification 학습 시에 더 깊은 layer를 사용할 수록, 더 풍부하고, 복잡한 형태의 representations를 학습하기 때문에, layer를 어떻게 더 효과적으로 쌓는지에 대해서 연구가 많이 되고 있다.
- ViT가 좋은 성능을 보이면서, 자연스럽게 ViT도 model을 깊게 쌓으면 CNN 처럼 성능이 좋아질 것인가? 에 대한 관심이 생기고 있다.
[ViT 깊이 실험]
- 이를 검증하기 위해, 각기 다른 block number의 ViT를 가지고 ImageNet classification 성능을 비교해보았다.
- 실험 결과, ViT 깊이가 커질수록 성능이 좋아지지 않는다는 것을 발견했고, 심지어 성능이 떨어지기도 하였다.
- 실험적으로 이유를 확인해 보았을 때, ViT의 깊이가 깊어지면, 특정 layer 이상에서 attention map이 비슷해지는 현상을 발생하였다. (즉, attention의 역할을 제대로 수행하지 못함.) 더 깊어지면, 아예 모든 값들이 같아짐을 확인했다.
- 즉, ViT의 깊이가 깊어지면 self-attention 방식이 더 이상 working 하지 않음을 의미한다.
[방법 제안]
- 이러한 "attention collapse" 문제를 해결하고, ViT를 효과적으로 scale 하기 위해, 이 논문에서는 간단하지만 효과적인 self-attention 방식인, "Re-Attention" 방식을 소개한다.
- Re-Attention은 Multi-Head self-attention 구조를 따르고, 다른 attention head들의 information을 이용하여, 좋은 성능을 내게 한다.
- 이 방식을 도입하면, 별도의 augmentation이나 regularization 추가 없이도, 더 깊은 block의 ViT를 효과적으로 학습하여, 성능향상을 확인할 수 있다. (SOTA)
Attention Collapse

- ViT에서 Transformer block 개수를 다르게 ImageNet Classification을 수행해 보았을 때, 기존 ViT에서는 block 개수가 커질수록 Improvement가 점점 감소되고, 심지어 성능이 줄어드는 것을 확인할 수 있다.
- 이 이유를 CNN에는 없는 self-attention 때문으로 지목했는데, model의 깊이에 따른 attention을 확인해 보았다.
- Transformer block이 32개 일 때, 각 block layer에서 다른 layer (인접한 k개의 layer) 와의 유사도를 구해본 결과 17번째 block을 넘어서는 순간 90% 이상의 거의 비슷한 output을 냄을 확인할 수 있다. 즉, 이후의 attention map들이 거의 비슷한 형태를 보이고, MHSA가 MLP를 악화시킬 수 있다는 것을 의미한다.

Re-Attention
- Attention Collapse를 해결하기 위해, 두 가지 방법을 제안한다. 첫 번째는, self-attention 연산을 위한 hidden dimension의 수를 늘리는 것이고, 두 번째는, re-attention 방식이다.
[Self-Attention in Higher Diemnsion Space]
- Self-Attention이 비슷해지는 것을 방지하기 위해, Dimension size를 늘리면, 더 많은 정보를 가지고 있게 되고, attention map이 더 다양해지고, 비슷해지지 않게 된다.
- 아래 그림과 표를 보면, 12 Block의 ViT에서 Dimension size를 늘렸을 때, 비슷한 Block들의 수가 줄어들면서, ImageNet 성능이 향상됨을 확인할 수 있다.
- 하지만, 이러한 방식은 성능적 한계가 있다는 점과, Parameter 숫자가 매우 늘었다는 단점이 있다.


[Re-Attention]
- 다른 Transformer block 사이의 attnention map은 매우 비슷하지만, 동일 transformer block에서 다른 head 사이에서는 similarity가 작음을 확인했다.
- 같은 attention layer의 다른 head들은 각기 다른 aspect에 집중하고 있기 때문이다.
- 이 결과를 바탕으로, cross-head communication을 위해, attention map들을 재생성하는 방식을 제안한다.
- 이를 위해, learnable parameter인 transformation matrix(H X H)를 개념을 도입하여, self-attention map의 head dimension 방향으로 곱해준다. 그 후 layer normalization을 진행하여 "Re-Attention" 구성한다.
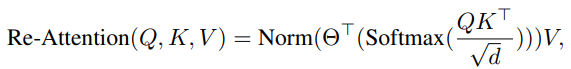
- Re-Attention의 장점은 크게 2가지이다. 첫 번째는 Re-Attention map은 다른 attention head 들 사이에 정보를 교환할 수 있어, 상호 보완이 가능하고, attention map의 다양성을 늘린다. 또한, Re-Attention map은 효과적이면서 간단하다.
→ 쉽게 말하면, self-attention을 진행할 때, 기존처럼 단순 softmax 값으로 값 참조를 하는 것이 아닌, 별도의 learnable parameter로 다양성을 향상하자는 개념임.
Experiments
- 실험에서는 attention collapse 문제에 대한 설명을 위한 실험을 진행한다. 추가적으로 Re-attention의 장점에 대한 추가적인 실험을 진행한다. (생략)
- 논문에서 주장한 것처럼 Re-Attention을 사용하였을 때, 비슷한 attention 패턴이 매우 줄고, 이로 인해 image classification에서 기존 ViT보다 더 높은 성능을 보인다. (ImageNet)

- Image Classification SOTA 모델들과 비교해 보았을 때도, 더 좋은 성능을 보인다.

Reference
ZHOU, Daquan, et al. Deepvit: Towards deeper vision transformer. arXiv preprint arXiv:2103.11886, 2021.
논문 총평
- 내 식견이 넓지 않은 까닭인지 저자들이 주장하는 Attention Collapse 현상과 Re-Attention 논리 구조를 100% 이해하진 못했다.
- 다만, CNN SOTA와 비견할 정도로 높은 성능을 보인다는 점에서 좋은 연구였다고 생각한다.
'Computer Vision' 카테고리의 다른 글
| Fine-tuning Image Transformers using Learnable Memory 논문 리뷰 (21) | 2023.12.12 |
|---|---|
| MobileViT 논문 리뷰 (57) | 2023.12.07 |
| DETR : End-to-End Object Detection with Transformers 논문 리뷰 (47) | 2023.11.07 |
| NaViT(a Vision Transformer for any Aspect Ratio and Resolution) 논문 리뷰 (1) | 2023.08.16 |
| ViT (Transformers for image recognition at scale) 논문 리뷰 (1) | 2023.07.13 |



