반응형
DETR 배경 설명
- DETR은 2020년 Facebook AI 팀에 의해 발표된 논문이다.
- Transformer를 Object Detection 분야에 최초로 적용한 논문이다.
Abstract
- 이 논문에서는 한 번에 물체의 위치와 classification을 진행할 수 있는 DETR이라는 새로운 네트워크를 소개한다.
- 기존에 Object Detection에서 존재하던 NMS(Non-maximum suppression)이나, anchor box 생성 같은 manual 작업들을 제거한 detection pipeline을 구성하였다.
- DETR의 주요 아이디어는 bipartite matching을 통한 unique predictions를 강제하는 "set-based global loss"와 transformer의 encoder-decoder 구조이다.
- object query가 있을 때, DETR은 object들과 전체적 이미지의 context 간의 관계를 추론하고, 이 정보를 기반으로 최종 예측을 병렬적으로 수행한다.
- 새로운 모델은 구조적으로 간단하고, 별도의 라이브러리를 사용하지 않는다는 장점이 있다.
- DETR은 accuracy와 run-time 측면에서 Faster R-CNN 기반의 최적화된 모델들에 버금갈 정도의 좋은 성능을 보인다.
Introduction
[배경]
- 기존 Object detection 방법들은 미리 구성해 놓은 anchor box를 이용하여, 많은 object들의 후보군을 만들어 놓고, 이를 regression과 classification을 통해, 예측하고, 비슷한 예측결과를 지우는(NMS) 과정들을 통해 진행된다.
- 이러한 과정을 간단하게 하기 위해, 이 논문에서는 이미지에서 직접 물체의 위치를 추론하는 방법으로 접근하고자 한다.
- 이미 음성인식등의 다른 분야에서는 이러한 end-to-end 방식이 성공을 거두었지만, object detection 분야에서는 이러한 시도들이 prior knowledge를 다른 방식으로 사용하거나, 성능 상에서 경쟁력이 없었다.
[소개]
- 이를 위해, 이 논문에서는 object detection의 학습 과정을 direct set prediction problem으로 접근한다.
- 논문에서는 transformer의 encoder-decoder 구조를 사용하였다. transformer의 self-attention 메커니즘은 비슷한 예측들을 제거하는데 적절한 constraints가 될 것이다. (아마, NMS를 대체할 수 있을 것이다.)
- DETR은 모든 object를 한번에 예측하고, 예측값과 ground-truth object들 간의 bipartite matching을 이용한 set loss function을 통해 end-to-end로 학습된다.
- 이를 통해서, 기존 object detection에서 prior knowledge를 담은 anchor box나 NMS 등을 제거할 수 있었다.
[기존 set prediction과의 비교]
- 기존의 direct set prediction과 비교하면, DETR은 bipartite maching loss와 transformer를 이용한 parallel decoding의 결합이 차이다.
- 기존 방식들은 RNN 방식에 의존하여, 예측 object들의 배열에 의존하는 것에 반해, DETR은 transformer를 이용한 parallel 연산으로 예측 object들의 배열에 의존하지 않는다.
[실험]
- DETR을 가장 많이 사용되는 object detection의 dataset인 COCO에서 Faster R-CNN 기반의 좋은 성능 모델들과 비교해 보았다.
- 최근(그 당시) 모델들은 최초 Faster R-CNN에서 구조 변화를 통해 성능이 크게 향상되었음에도 불구하고, DETR은 그들과 필적할만한 좋은 성능을 보였다.
- 조금 더 상세하게는, DETR은 large object들에 대해서는 더 좋은 성능을, small object들에 대해서는 더 낮은 성능을 보였다.
DETR Model
- DETR의 핵심요소는 (1) 예측과 ground truth 간의 unique matching을 만들어주는 set prediction loss와 (2) object 집합들을 예측하고, 그들 사이의 관계를 modeling 하는 아키텍처이다.
[object detection set prediction loss]
<1번째 : matching 구하기>
- 첫 번째로, DETR은 고정된 개수 N개에 대한 예측을 한다. 이때, N은 일반적인 이미지의 object 개수보다 큰 숫자이다.
- 이러한 구조의 학습과정에서 주요 이슈는 예측된 object를 ground truth와 어떻게 비교하냐이다. 이를 위해, 예측과 ground truth 간에 최적의 matching을 만드는 loss를 사용하였다.
- y가 object들의 ground truth이고, y는 no object의 class도 가질 수 있다고 할 때, 예측과 ground truth 간의 bipartite matching을 갖는 조합을 찾기 위해 아래 식을 계산한다.

- 위 식에서 L_match는 pair-wise matching cost인데, 이 는 class의 prediction과 예측과 ground-truth 간의 box 차이를 모두 고려한 cost이다.
- 이러한 방식은 기존 detector들의 방식의 anchor 등과 유사한데, 그들과의 차이점은 기존 detector에서는 비슷한 예측들이 많이 존재하는데, matching loss에서는 1대 1 매칭이 된다는 것이다.
<2번째 : loss 구하기>
- 두 번째로, 앞서 구했던 전체 matching 쌍들에 대해 Hungarian loss function을 계산한다. 이때의 loss는 일반적인 object detection의 loss와 비슷하게, class prediction에 대한 loss와 box loss의 합이다.
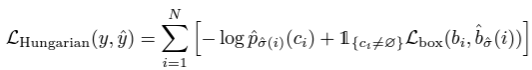
- 위의 식에서 우선 no object class의 matching cost는 prediction의 영향을 받지 않는다. (상수이기 때문에 학습 과정에서 영향을 미치지 않는다.)
- 위의 식에서 box loss를 구성할 때, 기존 object detection의 box loss와 달리, loss의 scale에 대한 이슈가 있다. (기존에는 anchor에 대한 상대적 위치를 loss로 썼기 때문에) 이를 해결하기 위해, box loss로 주로 사용되는 L1 loss 뿐 아니라, IoU loss를 추가적으로 사용했다.
- 따라서 box loss는 아래와 같다.
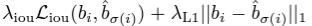
[DETR 아키텍처]
- DETR의 전체 아키텍처는 아래 그림에서 보이는 것처럼 매우 간단하다.
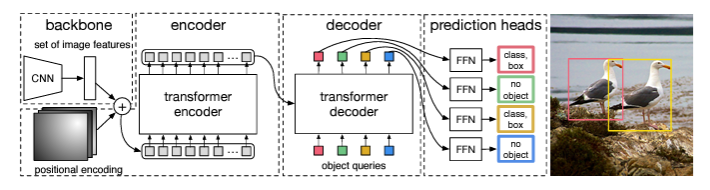
- DETR은 크게 3가지 주요 구조로 구성되어 있다. (1) compact feature를 뽑기 위한 CNN backbone (2) encoder-decoder transformer (3) 최종 예측을 위한 feed forward network(FFN)
- DETR은 Pytorch로 50줄 미만으로 inference code를 짤 수 있을 만큼 간단하다.
- Backbone : 이미지를 CNN backbone을 통과시켜, feature를 얻는다. 일반적으로 2048 X (H/32) X (W/32) shape의 feature를 뽑았다.
- Transformer encoder : 우선 1X1 convolution을 통해, channel dimension을 줄여줬다. encoder의 input으로 sequence 값이 필요하기 때문에, spatial 부분(H와 W)을 HW개의 sequence로 만들었다. encoder는 일반적인 transformer의 encoder이다. transformer 구조는 배열 순서에 무관하게 연산되기 때문에, 고정된 positional encoding 값을 더해서 이를 보충했다.
- Transformer decoder : decoder도 일반적인 transformer의 구조를 따랐다. 조금 다른 점은 DETR은 N개 object를 병렬적으로 각 decoder layer에서 연산하였다는 점이다. decoder도 마찬가지로 배열 순서에 무관하게 연산되기 때문에, positional encoding을 decoder의 각 attention layer에 추가하여 연산한다. decoder에 의해 N개의 object query들은 output embedding으로 변환되고, 각각 독립적으로 FFN에 의해 box coordinate와 class label을 예측하게 된다.
- FFN : 최종 prediction은 ReLU activation을 사용하는 3개의 layer에 의해 연산된다. FFN은 box의 중심 좌표와 height, width와 class label을 예측한다. 최종 N개의 결과가 나오는데, 이중 no object를 제외하고, 나머지들이 DETR의 최종 예측이 된다.
- Auxiliary decoding loss : auxiliary loss를 사용하는 것이 decoder의 학습 중 각 class의 정확한 object 개수를 추정하는 데에 도움이 된다는 것을 발견했다. 모든 prediction FFN은 parameter를 공유한다.
Experiments
- COCO dataset에서 Faster-RCNN 기반의 최근(그 당시) object detection model과 필적할 정도의 좋은 성능을 보인다.
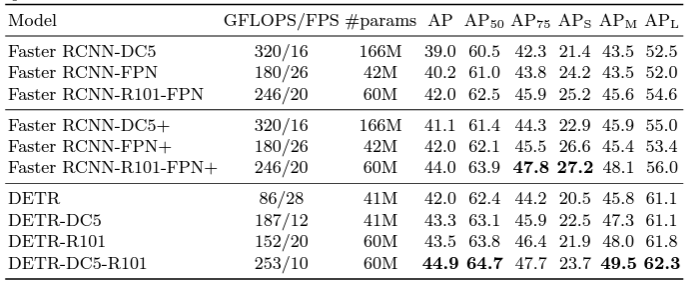
- 그밖에 encoder size나, selt-attention, segmentation에 적 등의 실험이 있다. 논문을 참조 바란다.
Reference
Carion, Nicolas, et al. "End-to-end object detection with transformers." European conference on computer vision. Cham: Springer International Publishing, 2020.
총평
- Transformer가 당연(?)하게도 OD 분야에 적용되었다. 2020년에 발표되어 늦은 감이 있지만, 지금이라도 읽어서 다행이다.
- Object Detection을 처음 접했을 때, anchor box를 사용하는 것과 NMS를 사용하는 것이 매우 비효율적이라고 생각하면서도 어쩔 수 없다고 생각하였는데, 결국 해결되는 것 같다.
- OD 논문을 열심히 읽어야겠다.
'Computer Vision' 카테고리의 다른 글
| Fine-tuning Image Transformers using Learnable Memory 논문 리뷰 (21) | 2023.12.12 |
|---|---|
| MobileViT 논문 리뷰 (57) | 2023.12.07 |
| DeepVit: Towards Deeper Vision Transformer 논문 리뷰 (1) | 2023.10.11 |
| NaViT(a Vision Transformer for any Aspect Ratio and Resolution) 논문 리뷰 (1) | 2023.08.16 |
| ViT (Transformers for image recognition at scale) 논문 리뷰 (1) | 2023.07.13 |



