반응형
MobileViT 배경 설명
- MobileViT은 2022년 Apple에서 ICLR 2022에 제출한 논문이다. (Apple이여서, mobile에 대한 CNN이 더욱 필요했을 것이다.)
- CNN에서 mobilenet이 나왔듯, ViT에서도 light cost에 초점을 맞춘 논문이 등장하였다.
Abstract
- mobile 환경에서 구동 가능할 정도의 가벼운 vision task CNN 모델이 등장하였었다. (mobilenet)
- 하지만, CNN과 달리 ViT는 최근 많은 vision task에 사용됨에도 불구하고, global representation들을 활용하기 위한 self-attention 구조를 사용하기 때문에, CNN에 비해 모델이 무겁다.
- 이 논문에서는 CNN과 ViT를 결합하여 mobile vision task에서 구동 가능한 가벼운 ViT 모델을 만들 수 있는가? 에 대한 답을 제시한다.
- 이를 위해, 가볍고, 좋은 성능을 내고, 다양한 용도로 사용할 수 있는 MobileViT를 소개한다.
- 실험에서는 MobileViT가 다양한 task와 dataset들에서 CNN과 ViT 기반의 모델보다 압도적인 성능을 보여준다.
Introduction
[배경]
- ViT의 소개 이후로, ViT의 연구 트랜드는 model의 parameter의 양을 늘리면서, 좋은 성능의 모델을 만들어내는 것이었다. (LLM처럼...)
- 하지만, 이런 모델 크기의 증가는 model의 용량 증가와 속도 저하등을 일으킨다.
- 실생활에서는 mobile 기기 같은 제한된 H/W에서 구동되어야 하는 task들이 많이 존재하기 때문에, 가볍고 빠른 모델에 대한 요구사항이 있다.
- 이를 위해, ViT의 parameter 개수를 줄이면, 오히려, 가벼운 CNN들보다도 좋지 않은 성능을 보여준다. 따라서, 어떻게좋은 성능을 유지하면서 가벼운 ViT를 만들 것인지에 대한 심도 깊은 고민이 필요하다.
[CNN + ViT]
- 일반적으로 ViT는 CNN에 많은 wieght를 필요로 하고, optimize가 어렵다. 예를 들어, ViT 기반의 segmentation network는 345 million의 parameter가 필요한데, 비슷한 성능의 CNN은 59 million으로, ViT 기반이 비효율적이다. 이것은 ViT가 CNN의 특성인 image specific inductive bias가 부족하기 때문이다.
- 좋은 성능의 ViT 모델을 위해서라면, convolution과 transformer의 하이브리드 방법을 채택하는 것이 효과적일 수 있다.
- 하지만, 기존 시도된 하이브리드 방법들은 아직 매우 큰 model size를 가지고 있고, data augmentation에 민감하다는 단점이 있다.
[MobileViT]
- 이 논문에서는 제한된 H/W 리소스에서도 효과적으로 좋은 성능을 보이는 ViT 모델을 만들고자 한다.
- 모델의 효율성 측정을 위해 보통 사용되는 FLops는 mobile 장비 등에서 성능 측정에는 충분하지 않다. 이는 FLOPs는 memory access나 parallelism 정도, platform 특성등을 고려하지 않기 때문이다.
- 따라서, 논문에서는 FLOPs을 optimize 하기보다는, light weight, general-purpose, low latency에 초점을 맞췄다.
- 이 논문에서는 CNN의 spatial inductive bias와 ViT의 global processing에 장점들을 결합가능한 MobileViT model을 소개한다.
- 특히, local 정보와 global 정보를 모두 encoding 할 수 있는 MobileViT block은 효과적인 representation을 포함한 feature를 만들 수 있게 해 준다.
MobileViT : A light-weight Transformer
- 일반적인 ViT model에서는 (H X W X C) 크기의 이미지를 P 사이즈의 patch들로 자르고, flatten 하고, projection 하여, (N X d) 크기의 inter patch representation으로 만든다. 이때, comnputational cost는 O(N*N*d)이다. (N: number of patch)
- 이러한 ViT 구조의 모델들은 CNN에 내재된 spatial inductive bias를 무시하기 때문에, CNN에 비해 더 많은 parameter를 필요로 한다.
- 또한, 이런 구조들의 모델은 L2 regularization이나, overfitting을 피하기 위해 많은 data augmentation이 필요한 등 optimization이 어렵다.
[MobileViT 아키텍처]
MiobileViT의 핵심 아이디어는 Transformer를 convolution으로 사용하여 global representation들을 학습하는 것이다.

- MobileViT block
- MobileViT block은 model이 input의 local과 global 정보를 적은 paramter 안에 모두 담을 수 있도록 하는 것이 목적이다.
- 우선 MobileViT는 (n X n) 개의 convolutional layer와 (1 X 1) convolution을 수행해 준다. 이로 인해, local representation을 포함하게 된다.
- global representation을 학습하기 위해, 앞서 covolutional layer의 output을 flatten 하고 겹치지 않도록, patch로 나눠준다. 그러고 나서, 이 patch들을 input으로 Transformer에 넣어준다.
- 이로 인해, 아래 그림처럼, local 정보를 포함하면서, global 정보까지 포함할 수 있는 feature가 완성되게 된다.

- Light Weight
- MobileViT는 image specific inductive bias를 사용할 수 있기 때문에, 일반 ViT에 비해 훨씬 더 가벼운 모델로 학습이 가능하다. (dimension 등을 줄일 수 있음)
- Computational Cost
- MobileViT와 ViT의 computational cost를 비교하면, 각각 O(N*N*P*d)와 O(N*N*d)로 이론적으로는 MobileViT가 더 비효율적으로 보인다. 하지만, 실제로는 MobileViT가 DeIT ImageNet-1K image classification에서 2배 적은 FLOPs으로 1.8% 좋은 성능을 낼 정도로 더 효과적이다.
- 이것은 더 가벼운 모델로 학습이 가능하기 때문이다.
[Multi-scale sampler for training efficiency]
- 일반적으로 ViT 기반의 모델들은 fine-tuning 시에 다양한 스케일의 representation들을 학습한다. 이 과정에서 Positional embedding을 사용하는데, 이는 input size에 기반하여 interpolation이 필요하고, interpolation 방법에 따라 성능에 영향을 미치게 된다.
- CNN과 마찬가지로, MobileViT에서도 이러한 positional embedding이 필요가 없다.
- MobileViT에서 이러한 다양한 스케일의 representation들을 학습하기 위해, batch size를 변경시키는 방법을 사용했다. 다양한 spatial resolutions set을 만들어 놓고, 각 bach 시, resoluton을 무작위로 뽑고, 해당 resolution에 따라 batch size를 유동적으로 변경하여 학습했다. (small spatial resolution에는 많은 batch)
- 이러한 학습 방법은 더 빠른 optimize가 가능하도록 하였다.
실험 결과
- MobileViT 모델을 scratch부터 ImageNet-1K classification dataset으로 학습했다.
- multi-scale sampler로 각각 (160,160), (192,192), (256,256), (288,288), (320,320) 해상도를 사용했다.
- 성능 측정은 top-1 accuracy로 진행했다.
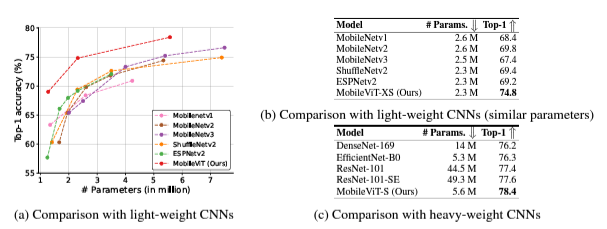
[CNN과 비교]
- MobileViT가 CNN 기반의 MobileNet 등의 light-weight CNN이나, ResNet 등의 일반적인 CNN의 성능을 압도했다.
[ViT 비교]
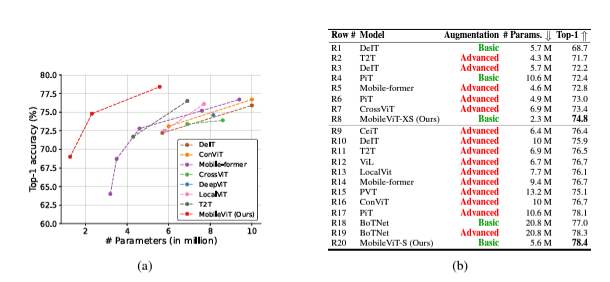
- ViT와 비교해서도 좋은 성능을 보인다. 특히, DataAugmentation에 따라 성능이 크게 바뀌는 다른 모델들과 달리, Basic Augmentation만으로도 다른 ViT보다 좋은 성능을 보인다.
총평
- 매우 아이디어가 간단하고, 효과적인 것 같다.
- 논문 내용만 보면, 장점만 많아서, 진짜인지 직접 돌려보고 싶다.
Reference
Mehta, S., & Rastegari, M. (2021). Mobilevit: light-weight, general-purpose, and mobile-friendly vision transformer. arXiv preprint arXiv:2110.02178.
'Computer Vision' 카테고리의 다른 글
| MobileViT v2 논문 리뷰 (34) | 2024.01.08 |
|---|---|
| Fine-tuning Image Transformers using Learnable Memory 논문 리뷰 (21) | 2023.12.12 |
| DETR : End-to-End Object Detection with Transformers 논문 리뷰 (47) | 2023.11.07 |
| DeepVit: Towards Deeper Vision Transformer 논문 리뷰 (1) | 2023.10.11 |
| NaViT(a Vision Transformer for any Aspect Ratio and Resolution) 논문 리뷰 (1) | 2023.08.16 |



