반응형
ViT 배경 설명
- ViT는 2021 ICLR에 나온, Google Brain의 논문이다.
- NLP 분야에서 광범위하게 사용되고 있던, Transformer를 computer vision 분야에 적용해 좋은 성능을 보여주었다.
Abstact
- Transformer가 NLP 분야에서는 standard로 자리 잡았지만, computer vision 분야에서 활용은 아직 한계가 있다.
- vision 분야에서는 attention은 attention은 CNN과 함께 적용되거나, 그 요소를 바꾸는 데 사용하는 등, 전체적인 구조는 그대로이다.
- 이 논문에서는 CNN구조의 중심이 불필요하고, image patches를 sequence 형태로 pure transformer에 바로 적용하는 것이 image classification에서 잘 working한다는 것을 보여준다.
- 많은 양의 pre-trained 데이터로 학습하고, 적은 양의 image recognition benchmark들로 실험했을 때, Vision Transformer(ViT)는 SOTA CNN 구조보다 학습에 적은 연산 cost를 사용하면서 좋은 성능을 낸다.
Introduction
[배경]
- NLP 분야에서는 Transformer를 선두로 한, Self-attention-based 구조를 채택해서, 매우 좋은 성능을 보이고 있다.
- Computer vision에서는 CNN 구조가 아직 대세이다. CNN 구조와 self-attention 구조를 연결하려고 노력하거나, conviolution을 대체하는 등 여러 연구들도 있었다.
- 특히, convolution을 대체하는 연구는 이론적으로는 효율적이지만, 현재(그 당시) hardware accelerator 구조로는 적용이 어려웠다. 따라서, large-scale image recognition에서는 classic resnet 구조가 아직 SOTA였다.
[소개]
- 이 논문에서는 standard Transformer를 거의 변경없이, 이미지에 적용한다. 이를 위해, image를 patch로 나누고, 이 patch들을 linear embeddings sequence 형태로 transformer에 넣는다. (image patche들은 NLP의 token처럼 다뤄진다.)
- 모델은 image classification을 supervised learning으로 학습한다.
- ImageNet 같은 mid-sized 데이터셋에서 이 모델은 비슷한 크기의 resnet보다 몇 % 정도 낮은 수준의 정확도를 보인다.
- 이 결과는 기대에 밑돌아, Transformer가 inductive biases(추상적 일반화)가 CNN에 비해 떨어진다고 생각할 수 있다.
- 하지만, 대용량 dataset에서 실험했을 때, 상황은 바뀐다.
- ViT는 충분한 pre-trained 데이터가 있을 때, 매우 좋은 성능을 보인다.
Method
- 모델 디자인은 original Transformer를 최대한 비슷하게 따랐다. (구현이 되어 있기에 바로 적용할 수 있어서)
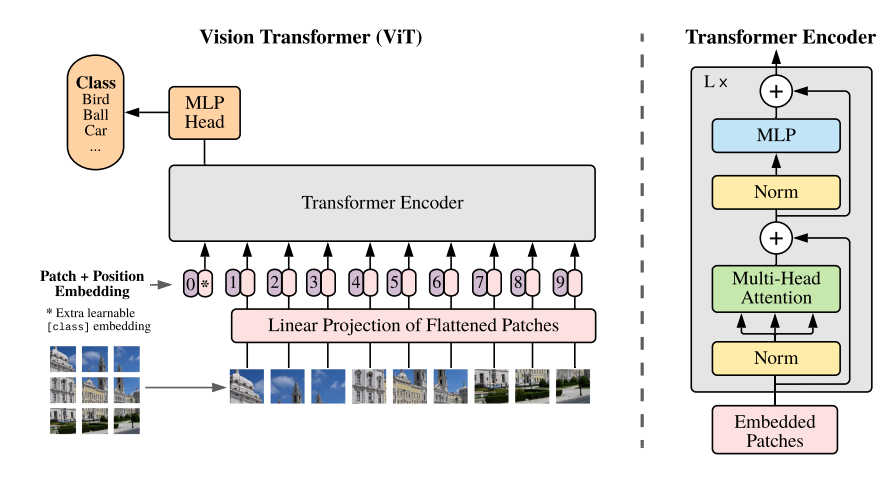
[ViT]
- Transformer는 1D 데이터를 처리하는데, 이미지는 2D이다. 이미지(HXWXC)를 다루기 위해, Image를 2D patches(PXPXC) 개로 나누었다.
- Transformer는 각 layer에서 constant latent vector size D를 유지하는데, 이를 위해, patch들을 학습 가능한 linear projection을 통해, D dimension 화하였다. 그리고, 이 결과를 patch embeddings라고 부른다.
- BERT의 class token 처럼, patch embedding의 앞에 learnable embedding을 붙인다. 이것은 Transformer encoder의 output이 이미지 representation(y)이 될 수 있도록 사용된다.
- pre-training과 fine-tuning 단계에서 모두, Transformer encoder의 ouput이 classification의 head로 이용된다.
- classification head는 pre-training 단에서는 one hidden layer의 MLP로, fine-trurning 단계에서는 하나의 linear layer로 구성된다.
- Position embeddings는 patch embeddings에 더해져, 공간 정보를 제공한다.
- ViT에서는 학습 가능한 1D position embeddings를 사용했는데, 2D의 position embedding이 성능에 딱히 영향이 없는 것 같아서 그랬다고 한다.
- Transformer encoder는 multiheaded self-attention의 대체 layer들과 MLP block으로 구성되어있다.
- Layernorm은 각 block 전에 적용되어 있고, 모든 block 끝에는 residual connection이 존재한다.
- MLP는 GELU 함수를 사용한 2개의 latyer로 구성되어 있다.

[Inductive bias]
- ViT는 image specific inductive bias가 CNN에 비해 덜하다.
- CNN에서는 지역 정보, 2D neighborhood 정보, translation 등분산성(골고루 보고 처리한다.)이 각 layer에 담긴다.
- ViT에서는 MLP layer에서만 translation 등분산성과 지역 정보를 보고, self-attention layer들에서는 전체적으로 본다.
- 2D neighborhood 정보는 드물게 사용된다. model의 시작에 이미지를 cutting 하고, fine-tuning 때는 position emeddings를 다른 resolution으로 처리하기 때문이다. 또한, initinalization 시에 embedding에는 정보가 없기 때문에, patch의 2D 위치와 patch 간의 공간 관계에 대해 처음부터 스스로 학습해야 한다.
[Hybrid Architecture]
- raw image patches의 대안으로, CNN의 feature 형태로 input sequence를 구성할 수 있다. hybrid model에서는 patch embedding을 CNN feature map으로부터 뽑는다.
- 어떤 케이스에서는 1X1이 될 수 있는데, 이 것은 input sequence가 spatial dimension 정보를 flatten 한 케이스이다.
- classification input embedding과 postion embeddings들은 아래처럼 더해진다.
[Fine-turning and Higher resolution]
- 기본적으로 ViT를 large dataset에서 pre-train 하였고, 적은 데이터셋에서 fine-tune 하였다.
- 이를 위해, pre-trained prediction head를 지우고, zero-initialized D X K layer를 넣었다. (K는 classification class 개수)
- pre-trained 보디, fine-tune 때 높은 해상도의 이미지를 사용하는 것이 유리하다.
- 고해상도 이미지를 넣을 때, patch size는 동일하게 유지한다. (sequence length만 늘어난다.)
- ViT는 임의의 sequence length를 다룰 수 있지만, 그러면 pre-training 된 position embedding은 더 이상 의미가 없다.
- 이때는 pre-trained position embedding에 original image에서의 위치에 따라, 2D interpolation을 통해 처리했다.
Experiments
- Resnet, ViT, hybrid model을 실험했다.
- 각 모델의 데이터 필요도를 확인하기 위해, 다양한 사이즈에서 pre-train을 하였고, 다양한 benchmark에서 실험했다.
- pre-training의 연산 cost를 생각했을 때, ViT는 매우 순조롭게, 적은 양의 연산 cost 만으로 SOTA recognition benchmark에 도달했다.
[Setup]
- Dataset : ILSVRC-2012 ImageNet 데이터셋(1000 classes, 1.3M images), superset ImageNet-21k(21k classes, 14M images), JFT(18k classes, 303M high resolution images)을 사용했다. benchmark로는 ImageNet의 original validation labels와 cleaned-up Real labels, CIFAR-10/100, Oxford-IIIT Pets, Oxford Flowers-102를 사용했다.
- Model Variants : ViT의 configuration는 BERT를 기반으로 했다. patch size가 작아질 수 록 연산은 expensive 해진다. (token이 많다고 생각하면 됨) CNN의 baseline으로는 ResNet을 사용했지만, Batch Normalizaation layer를 Group Normalization으로 대체했다.
[SOTA와 비교]
- 특정 모델에서 ImageNet의 SOTA인 NoisyStudent보다 좋은 성능을 보여준다.


Conclusion
- image recognition에 Transformer를 사용해 보았다.
- 과거 computer vision에서의 self-attention 구조와 다르게, image-specific inductive biases를 구조에 넣지 않았다.
- 대신에, 이미지를 patch들의 sequence로 다뤄, NLP처럼 처리했다.
- scalable 하고, large dataset에서 pre-training 했을 때, 잘 working 하여, ViT는 pre-trained에 많은 cost를 쓰지 않고도, SOTA image classification에 버금가는 성능을 보여주었다.
- 아직, 나아갈 길이 많다. (detection이나 segmentation 적용 등)
Reference
Dosovitskiy, Alexey, et al. "140 Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, 141 Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image 142 recognition at scale." ICLR 3 (2021): 143.
총평
- NLP 분야에서 혁신을 이뤄낸, transformer를 vision 분야에 도입하여 성능을 낸 게, 지금 시점에서는 당연해 보이지만, 이 도입을 위해 얼마나 고민하고, 실험했을지 싶다.
- NLP처럼 transformer를 시작으로, GPT, BERT 등으로 이어지는 거대 모델의 흐름이 vision에도 적용될 것인지 살펴봐야겠다.
'Computer Vision' 카테고리의 다른 글
| Fine-tuning Image Transformers using Learnable Memory 논문 리뷰 (21) | 2023.12.12 |
|---|---|
| MobileViT 논문 리뷰 (57) | 2023.12.07 |
| DETR : End-to-End Object Detection with Transformers 논문 리뷰 (47) | 2023.11.07 |
| DeepVit: Towards Deeper Vision Transformer 논문 리뷰 (1) | 2023.10.11 |
| NaViT(a Vision Transformer for any Aspect Ratio and Resolution) 논문 리뷰 (1) | 2023.08.16 |










