반응형
NaViT 배경 설명
- NaViT은 Google DeepMind에서 2023년 7월(리뷰 시점에서 1달 전)에 나온 논문이다.
- Model 크기에 맞게 Input size를 조정하던 기존의 CNN 구조에서 벗어나, ViT로 다양한 resolution의 input을 학습하고자 하였다.
Abstact
- computer vision model에서 이미지 처리 전에 고정된 이미지 resoultion은 최적이 아님에도 불구하고, 보편적으로 사용된다.
- ViT 같은 모델은 flexible한 sequence-based modeling을 제공하기 때문에, input sequence 길이를 가변적으로 사용 가능하다.
- 이 논문에서는 ViT의 특징을 이용한, 학습과정에서 무작위의 resolution과 aspect ratio을 다룰 수 있도록 하는 sequence packing을 사용했다.
- 이 논문에서는 large-scale의 supervised 및 contrastive image-text pretraining을 통해 모델의 효과성을 보여준다.
- 또한, 이 모델은 image, video classification이나, object detection, semantic segment등에 transfer 되어, 성능 향상에 사용될 수 있다.
- inference time에서, input resolution의 유연성은 time cost와 performance의 trade-off 사이에서 최적을 찾을 수 있게 한다.
Introduction
[배경]
- ViT는 간단하고, flexible, scalable 하며, 기존 CNN의 대체로 사용할 수 있다.
- ViT는 input image들을 resize 하고, 고정된 aspec ratio의 patch들로 잘라서, 모델의 input으로 사용한다.
- 최근 고정된 aspect ratio을 사용하는 것을 대체할 방법을 제시하는 논문들이 등장하고 있다.
- FliexiViT는 다양한 patch size를 하나의 architecture에서 다룬다. 이것은 각 training step에서 patch size를 random sampling 하고, reszing algorithm이 초기 convolutional embedding이 다양한 patch size를 다룰 수 있게 하기 때문이다. (이 논문도 읽어 봐야겠다.)
[소개]
- 이 논문에서 다른 이미지들에서의 여러 patch들이, single sequence로 묶여 처리하는 NaViT라는 모델을 소개한다. 논문의 아이디어는 NLP에서 다양한 example들을 singlel sequence로 처리하는 example packing에서 영감을 받았다.
- NaViT은 다음과 같은 장점이 있다.
- 학습 과정에서 training cost를 줄이기 위해, resolution을 randomly sampling 한다.
- NaViT는 다양한 resolutons에서 좋은 성능을 보이고, cost-performance가 smooth 한 trade-off를 제공한다.
- 고정된 batch shape은 aspect-ratio preserving resoltion sampling이나, variable token dropping rates, adaptive computation 등의 새로운 아이디어를 이끈다.
- 동일한 computational cost 내에서, NaViT는 ViT를 능가하는 성능을 보인다. 이는 NaViT 한정된 computational cost 내에서 더 많은 양의 training example을 처리할 수 있기 때문이다.
- 향상된 efficiency는 fine-tuning process에서도 이어진다. NaViT는 pre-training과 fine-tuning에서 다양한 resolution으로 학습되었기 때문에, 무작위 resolution으로 평가하였을 때, NaViT는 더욱 효과적이다.
Method
- 기존 딥러닝 모델들은 fixed 된 이미지 사이즈를 사용한다. 이를 위해, 이미지를 resizing 하거나, padding을 하는데, 성능이 떨어지고, 비효율적이다.
- 한편, Language Modeling에서는 example packing(다양한 example들을 하나의 sequence에 묶어서 학습을 가속화함)을 이용하여, 고정된 sequence length의 한계를 넘는다.
- 이 논문에서는 image를 token으로 대하여, ViT도 같은 방법으로 효과를 볼 수 있음을 보여준다. 이를 Patch n'Pack이라 명명한다. 또, 이미지가 native resolution으로 학습될 수 있기 때문에, 이 모델을 NaViT로 명명한다.
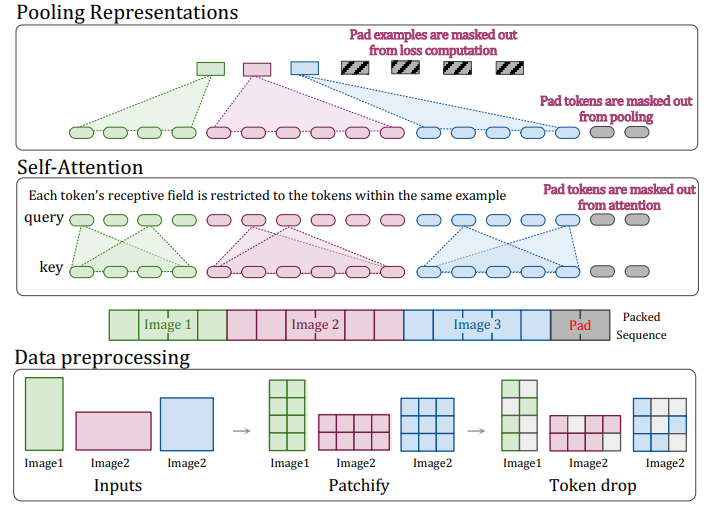
[구조 변화]
- NaViT는 ViT를 기반으로 만들어졌다. Patch n'Pack을 가능하게 하기 위해, 몇 가지의 구조적 변화를 주었다.
1. Masked self attention and masked pooling
- example들이 서로 겹치는 것을 막기 위해, self-attention masked를 추가하였다.
- 마찬가지로, encode 최상단의 masked pooling은 token을 pooling 하는 것을 목표로 한다. sequence 내의 각 example은 single vector representation으로 표현된다.
2. Factorized & fractional positional embeddings
- 무작위 resolution과 aspect ratio를 다루기 위해, factorized position embeddings를 제안한다.
- factorized position embeddings에서는 embeddings을 x방향과 y방향으로 decomposition 하고, 각각 합해진다.
- 2개의 스키마를 고려하였는데, absolute embeddings와 factional embeddings이다. 특히, fractional embeddings는 상대적 거리이기 때문에, 이미지 사이즈와 무관하지만, original aspect ratio가 깨질 수 있다.
- 학습한 embedding과 sinusoidal embeddings, NeRF를 사용하여 학습된 Foueier positional embeddings을 고려한다.
[Training changes]
- Patch n' pack을 이용하여 학습과정에서 몇가지 새로운 테크닉을 사용할 수 있다.
1. Continuous Token Dropping
- Token dropping (학습 과정에서 input patch를 무작위로 빼는 것)은 학습을 빠르게 하기 위해 고안되었다.
- 기존 Token dropping에서는 모든 example들에서 동일한 비율로 token이 drop 되지만, continuous token dropping은 이미지마다 drop 비율이 달라질 수 있다.
- 이로 인해, 학습이 빨라지고(처리 token 양이 줄기 때문) , 학습 시에 완전 이미지(drop 안 한 이미지)도 같이 학습할 수 있다는 장점이 있다.
2. Resolution sampling
- NaViT은 original image의 aspect ratio를 유지하면서, random sampling 된 사이즈를 이용한다.
- original ViT에서는 작은 이미지를 통해 throughput이 커지면, performance도 증가하는 특징을 가지고 있다.
- NaviT은 다양한 resolution을 학습 시에 사용하기 때문에, 높은 throughput과 큰 이미지로 학습이 모두 포함되기 때문에, original ViT보다 성능 향상을 보인다.
[Efficiency of NaViT]
- NaViT의 computational cost에 대한 장이다.
1. Self attention cost
- 원래 이미지의 patch를 자를수록 computational cost가 매우 증가하지만(quadratic 하게), Transformer의 hidden dimension이 늘리면, computational cost가 original image를 한 번에 처리하는 것보다 아주 조금만 늘어난다.
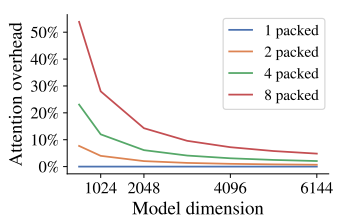
- 매우 긴 sequence를 사용하면, memory cost가 많아, 속도가 느려지는 현상이 있는데, memory-efficient 방법을 사용하여 이 문제를 해결하였다.
2. Packing, and sequence-level padding
- prediction을 위한 최종 sequence length는 동일해야 한다.
- 길이를 맞추기 위해, example들을 perfect combination 하는 것이 아닌, fixed length가 되도록, 더해서 맞추거나, padding을 사용한다.
- padding 되는 toekn은 전체의 2% 이하이기 때문에, 간단한 방법으로 충분하다.
3. Padding examples and the contrastive loss
- per-token loss가 직관적이지만, 많은 computer vision model들은 example 단위의 loss를 구한다.
- 이를 도입하기 위해서는 example 개수의 max를 정해놓고, 그 이상은 drop 하는 방법을 사용한다. 그런데, 이럼 학습 시에 아무것도 학습하지 않지만, computational cost를 낭비하는 상황이 발생한다.
- contrastive learning은 이 상황에 취약한데, time과 memory의 loss computational scale이 quadratic 하게 증가한다.
- 이를 방지하기 위해, chunked contrastive loss라는 방법을 사용하는데, softmax 계산을 위해 모든 데이터를 모으는 것이 아닌, local device subset에 각각 데이터를 모으고, global softmax normalization을 위한 통계값만 뽑는 형식이다.
- 이로 인해, 최대 example 수를 늘릴 수 있다.
Experiments
- NaViT은 기본적으로 original ViT을 따랐다.
- NaViT을 2개 setup으로 학습했다. classification training으로 JFT-4B를 사용했고(sigmoid cross-entropy loss 사용), contrastive language-image training으로 WebLI를 사용(contrastive image-text loss 사용)했다.
- FLAX library를 이용했고, JAX로 구현했다.
[Improved Training Efficiency and performance]
- 동일 computational cost에서 NaViT은 ViT을 능가한다.
- 동일 성능(Accuracy)을 위해, NaViT은 ViT보다 4배 이상의 빠르게 학습되었다.
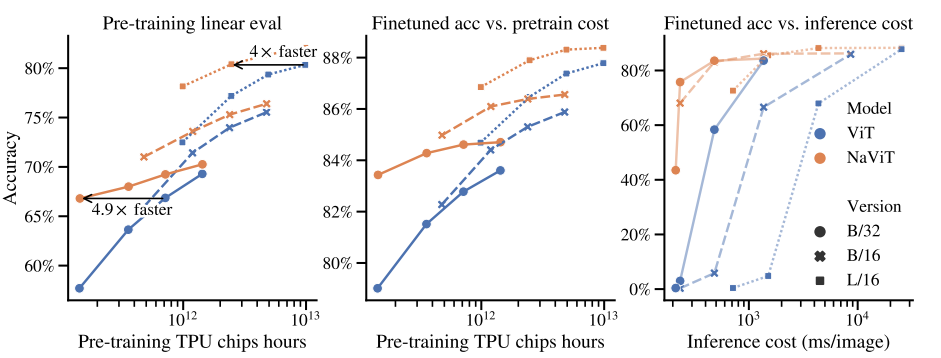
[variable resolution의 장점]
- variable-resolution pre-training : fixed image로 학습한 최고의 결과도 variable resolution과 동일할 정도로, variable resolution이 우위에 있다.
- variable-resolution fine-tuning : variable resolution으로 fine-tuning 한 게 성능이 더 좋고, fine-tuning을 low resolution으로 했더라도, higher resolution에 대한 성능을 유지하는 것을 보여준다.
Reference
Dehghani, Mostafa, et al. "Patch n'Pack: NaViT, a Vision Transformer for any Aspect Ratio and Resolution." arXiv preprint arXiv:2307.06304 (2023).
논문 총평
- 아이디어가 매우 간단하고, 직관적이여서 좋았다.
- 사실 아이디어도 중요하지만, 소스가 JAX로 짜놨다고해서, 코드를 한 번 보고 싶다!
'Computer Vision' 카테고리의 다른 글
| Fine-tuning Image Transformers using Learnable Memory 논문 리뷰 (21) | 2023.12.12 |
|---|---|
| MobileViT 논문 리뷰 (57) | 2023.12.07 |
| DETR : End-to-End Object Detection with Transformers 논문 리뷰 (47) | 2023.11.07 |
| DeepVit: Towards Deeper Vision Transformer 논문 리뷰 (1) | 2023.10.11 |
| ViT (Transformers for image recognition at scale) 논문 리뷰 (1) | 2023.07.13 |



