반응형
항상 문제에 봉착하기 전에는 내가 모르는 것이 뭐인지 모르게 된다. 항상 Batch Normalization은 당연하게 사용하였지, 그 의미에 대해서 대략적으로만 알고 있었던 것 같아서, 이번 기회에 Batch Normalization의 논문을 읽으면서 기본기부터 다시 쌓고자 한다.
Batch Normalization 배경 설명
- Batch Normalization은 딥러닝을 접해본 사람이면, 누구나 알 것이다. Batch Normalization은 2015년 구글에서 ICML에 발표한 논문이다.
- Internal Covariate Shift 문제를 정의하고, 이를 해결하기 위한 mini batch 단위의 Normalization 방법에 대해서 제안한다.

Abstract
- DNN의 학습 과정에서 앞선 layer들의 parameter 변화에 따라, 뒷 layer들의 input의 분포가 변하기 때문에 학습이 매우 어렵다.
- 이 현상으로 인해 학습의 learning rate를 크게 가져가지 못하고, parameter 초기화를 신중히 해야 한다. 따라서, 비선형성 모델의 학습을 느리게 만든다.
- 이 논문에서는 이 현상을 "internal covariate shift"라 부르고, 이를 해결하기 위해, layer의 input을 normalize 하는 방법을 사용한다.
- 이 모델에서는 normalization을 model 아키텍처의 일부분으로 각 training mini-batch마다 normalization을 수행하는 방법을 사용한다.
- Batch Normalization을 통해, 더 높은 learning rate를 사용할 수 있고, 모델이 parameter 초기화에 덜 민감해지게 된다. 또한, regularizer로 작동하기 때문에, 일부 상황에서는 Droupout을 대체하기도 한다.
- 그 당시 SOTA image classification model에 적용하여, Batch Normalization은 training step을 14 단계나 줄이면서 비슷한 accuracy를 달성하였다.
Introduction
[배경]
- stochastic gradient descent(SGD)는 deep network 학습에 효과적인 방법이라는 것이 밝혀졌다. SGD의 변형 버전들은 SOTA 성능을 이끌고 있다.
- SGD는 parameter를 optimize 하기 위해 loss를 minimize 한다. SGD에서 학습은 단계적으로 이뤄지고, 각 학습의 단계는 mini batch로 여겨진다. 이 mini-batch는 loss function의 gradient를 추정하기 위해, 아래와 같은 식을 사용한다.
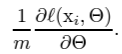
- mini-batch들을 사용하면, 데이터를 하나씩 학습하는 것에 비해 몇 가지 장점이 있다.
- mini-batch를 통해 구해진 loss의 gradient를 통해, training set의 gradient를 추정할 수 있다.
- bach 계산은 병렬 연산을 이용하기 때문에 각 example을 m번 연산하는 것보다 효과적이다.
[문제]
- 이렇게, SGD는 간단하고 효과적이지만, model hyper-parameter를 신중하게 tuning 해야 한다. 특히, 앞선 layer들의 parameter 변화가 뒷 layer들에 영향을 미치기 때문에, model parameter나 learning rate 같은 hyper parameter 선택 시 주의를 요한다.
- 특히, layer input의 분포 변화는 layer들이 새로운 분포를 계속 처리해야 하는 문제를 야기한다. 이러한 input 분포의 변화를 covariate shift라 한다. 예를 들어, 아래와 같은 gradient descent step 연산이 있을 때, x (input 값)이 고정된다면, parameter는 x의 새로운 분포에 적응하는데, 연산을 낭비하는 것 없이, parameter optimize에 집중할 수 있다.
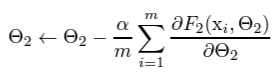
- 추가적으로, 이런 고정된 input의 distribution은 다른 장점을 가진다. 예를 들어, sigmoid를 생각해 보았을 때, sigmoid의 input의 절댓값이 커지면(큰 음수값을 가질 때), sigmoid의 값은 0에 가까워진다. 이는, 학습의 속도를 늦추게 된다. 이러한 현상은 모델의 깊이가 깊어질수록 가속화되는데, 이러한 현상(staturation problem으로 야기된 gradient vanishing)을 실제 학습에서는 ReLu function과 좋은 parameter initialization, 또는 작은 learning rate 적용을 통해 방지하곤 한다.
- 하지만, 이러한 비선형의 input들이 조금 더 안정적인 분포를 띄게 된다면, optimizer는 saturate에 덜 빠지게 되어, 학습이 가속화될 것이다.
- 이 논문에서는 deep network의 internal node의 분포 변화를 "internal Covariate Shift"라고 명명하고, 이것을 없애면 더 빠른 학습이 된다는 것을 밝힌다.
[Batch Normalization]
- 이를 위해, "Batch Normalization"이라는 방법을 소개한다. 이 방법은 input layer들의 평균과 분산을 고정된 값으로 normalization 하는 과정을 포함한다.
- Batch Normalization을 사용하면, parameter들의 초깃값의 scale에 따른 gradient scale의 민감도를 줄여줘서, divergence 위험 없이 더 큰 learning rate를 선택할 수 있게 해 준다.
- 추가적으로 Batch Normalization은 model을 regularize 해줘서, Dropout의 필요성을 줄여준다.
Internal Covariate Shift를 줄이기 위한 방법
- 이전부터, input을 whitned(평균 0, 표준편차 1의 값)하게 되면 network training이 빠르게 수렴된다는 것이 알려져 있었다.
- whiening을 모든 학습 과정이나, 일정한 interval 단위로 network를 직접 바꾸거나, optimization algorithm을 활용한 parameter 변경을 할 수 있지만, 이러한 변화들이 optimization 단계에서 gradient step의 영향을 줄여, 학습의 속도를 저하시킬 수 있다. (normalization이 되기 때문에)
- 만약, network가 항상 원하는 형태의 분포를 갖게 된다면, loss에 대한 model parameter의 gradient가 normalization을 고려하고, model parameter에 대한 의존성을 동시에 고려할 수 있게 된다.
- x가 layer input vector이고, X가 training dataset의 전체의 input vector 집합이라고 할 때, normalization은 다음과 같이 계산될 수 있다

- 이 식의 backpropagation을 위해서 Jacobian을 계산해야 하는데, 아래 식에서 두 번째 term을 무시하면 explosion이 일어날 수 있다. 이 framework에서 layer의 input을 normalization 하기 위해서는 매우 큰 비용이 드는데, covariance matrix를 구해야 하기 때문이다.

- 이를 해결하기 위해, 저자들은 미분 가능한 다른 대안을 생각해 보았고, 앞서 통계적 방법이나 feature map들을 사용한 방법들이 있었지만, network의 성능을 떨어뜨릴 수 있기 때문에, network의 정보를 유지하면서 전체 training data의 통계값에 대한 trainign example을 normalization 하는 방법들을 고안하게 된다.
Mini-Batch 통계값을 이용한 Normalization
- 각 scalar feature들을 독립적으로 평균 0, 분산 1을 갖도록 normalize 한다. input들의 모든 dimension을 아래와 같이 normalization 한다.

- 단순히, 위처럼 input을 normalization 하면, 각 layer의 output 값들이 변경될 수 있기 때문에, 아래처럼 original model param을 구해 준다. 이때, gamma과 beta는 학습가능한 parameter이다. 즉, normalization 한 값을 original 값으로 돌리기 위한 parameter들을 학습하는 것이다.
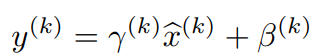
- Normalize를 위해 전체 training set을 모두 통계내는 것은 비효율적이다. 따라서, mini-batch의 개념을 이용하여, 각 mini-batch에서 평균과 분산을 계산한다. (즉, batch 내에서 각 dimension에 대한 평균과 분산을 구한다.)
- 이 과정을 Batch Normalization이라고 하고, 그 자세한 과정은 아래와 같다.

- Batch Normalization은 단순히 하나의 batch 내에 있는 training example들에 의존하는 것이 아니라, 다른 mini-batch들을 고려할 수 있게 된다. 이를 통해, 모델의 학습 과정에서는 항상 평균이 0이고, 분산이 1인 input, 즉 고정된 distribution이 사용되게 된다.
CNN에서 Batch Normalization
- Batch Normalization은 CNN에도 적용할 수 있는데, 아래와 같은 식이 있다고 할 때, (u: layer input, g: activation function, W: weight, b: bias) Convolutional layer 직후 (activation function 전)에 Batch Normalization을 걸어 줄 수 있다.

- BN을 model input인 u에 걸어주지 않는 이유는, model input은 다른 nonlinearity의 output이기 때문에 (전 layer의 activation function의 결과이기 때문에) 분포가 학습과정에서 계속 바뀔 수 있기 때문이다. 반면에, convolutional layer 직후(Wu+b)는 더 대칭적이고, non-sparse 한 분포를 띌 가능성이 높고, 더 "Gaussian"하기 때문에 조금 더 안정적인 distribution을 만들 수 있다고 한다. b는 합항이기 때문에 당장 고려하지 않아도 된다. (어차피 학습될 Beta가 해당 값을 포괄할 수 있기 때문에) 따라서, layer의 output은 다음과 같이 나타낼 수 있다.
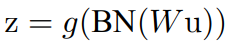
- convolutional layer에서는 BN을 위해, 각 mini batch에서 모든 위치에 걸쳐 공통적으로 정규화하는 방법을 사용하고 있다. (즉, 기존은 dimension 단위의 normalization이었다면, 이번엔 feature의 spatial 부분까지 고려한 normalization이다.) 따라서, learned parameter인 gamma와 beta도 feature map의 크기를 갖는다.
Batch Normalization으로 인한 high learning rate 사용 가능
- 기존 deep network에서 큰 learning rate를 적용하면 gradient의 explosion이나 vanish가 일어나게 되어, local minima에 빠지게 된다.
- Batch Normalization은 parameter의 변화로 인한 gradient의 큰 변화를 방지하여, high learning rate를 사용 가능하게 해준다.
실험 결과
[batch normalization으로 인한 high learning rates 사용 가능]
- batch normalization으로 인해 큰 learning rates를 사용할 수 있게 되었다.
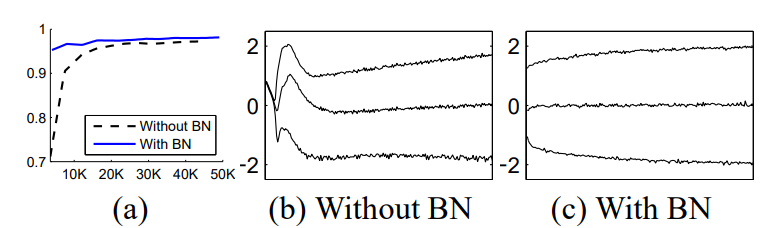
[ImageNet Classification]
- 아래 그래프의 가로축은 training step이고 세로축은 validation accuracy이다. Batch Normalization을 이용하면 더 적은 step에서 좋은 성능을 발휘하는 것을 확인할 수 있다.


Reference
Ioffe, Sergey, and Christian Szegedy. "Batch normalization: Accelerating deep network training by reducing internal covariate shift." International conference on machine learning. pmlr, 2015.
총평
- 당연히 Batch Normalization에 대해 이해하고 있다고 생각했고, 따로 논문 찾아볼 생각을 안했는데, 읽기를 잘했다.
- 논문이라는 게 문제를 정의하고 푸는 과정이기 때문에, "왜?" 쓰는지를 깊이 알려면, 논문을 직접 읽는 게 나은 것 같다.
'머신러닝' 카테고리의 다른 글
| Layer Normalization 논문 리뷰 (1) | 2024.04.01 |
|---|---|
| Group Normalization 논문 리뷰 (25) | 2024.03.28 |
| Decision Tree(의사결정나무 ) (17) | 2023.08.29 |
| t-SNE(t-distributed Stochastic Neighbor Embedding) (1) | 2023.04.26 |
| Logistic Regression(로지스틱 회귀 분석(2)-다중 분류) (1) | 2023.04.23 |



