반응형
이상치 제거에서 통계적인 방법은 유용하게 사용되지만, 다루는 데이터가 복잡하고, 차원이 커질수록, 단순 분포의 개념을 활용하기는 어렵다. 이를 해결하기 위한, 이상치 제거 방법 중, 머신 러닝 기반 방법들을 몇가지 알아보기로한다.
머신러닝을 이용한 이상치(Outlier) 제거 방법
1. Cook Distance를 이용한 방법
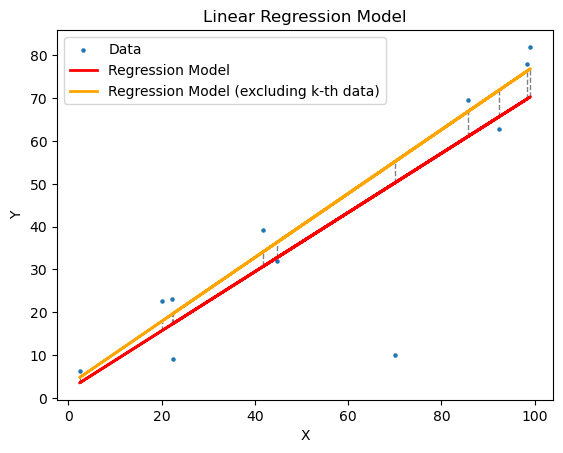
- Cook Distance는 회귀분석 문제에서 이상치를 찾기 위해 많이 사용되는 방법이다.
- 각 데이터포인트가 회귀분석 모델의 예측력에 어느 정도 영향을 미치는지를 확인하여, 이상치 제거에 활용할 수 있다. (해당 데이터 포인트를 제거한 모델이 오히려 더 좋은 예측력을 가질 때, 해당 데이터 포인트를 이상치로 간주할 수 있다. )
- Cook Distance를 이용한 이상치 제거의 단계는 다음과 같다.
- 데이터 전체를 이용해서, 회귀 모델을 예측한다.
- 각 데이터 포인트를 제외한 데이터들로 회귀 모델을 예측한다.
- Cook Distance를 구한다.
- Cook Distance가 일정 값 (일반 적으로 1) 이상인 값들은 이상치로 취급한다.
- Cook Distance의 수식은 다음과 같다.




- 파이썬 코드 구현
- 파이썬의 statsmodels 패키지를 사용하면, 쉽게 Cook Distance를 구할 수 있다.
import numpy as np
import statsmodels.api as sm
if __name__ == '__main__':
x = np.random.rand(10)*100
y = 0.8*x+np.random.randn(10)*5
alpha = 70
beta = 10
X = np.append(x,alpha)
Y = np.append(y,beta)
model = sm.OLS(Y, X).fit()
influence = model.get_influence()
cd, _ = influence.cooks_distance
outliers = np.where(cd > 1)[0]
2. DBSCAN을 이용한 방법
- DBSCAN(Density-Based Spatial Clustering of Applications with Noise)은 머신 러닝에 주로 사용되는 클러스터링 알고리즘으로 Multi Dimension의 데이터를 밀도 기반으로 서로 가까운 데이터 포인트를 함께 그룹화하는 알고리즘이다.
- DBSCAN에 대한 자세한 내용은 https://devhwi.tistory.com/7을 참고하면 된다.
- DBSCAN에서 어느 Cluster에도 속하지 못한 데이터들을 Outlier로 판단한다.


- 파이썬 코드 구현
- 파이썬의 statsmodels 패키지를 사용하면, 쉽게 Cook Distance를 구할 수 있다.
from sklearn.cluster import DBSCAN
import numpy as np
from sklearn.datasets import make_blobs
if __name__ == '__main__':
X, y = make_blobs(n_samples=1000, centers=5, random_state=10, cluster_std=1) # 데이터 생성
x = np.array([[-7.5,-3]]) # 이상치 데이터
X = np.concatenate((X,x), axis=0)
# DBSCAN 알고리즘 적용
dbscan = DBSCAN(eps=1.5, min_samples=2)
dbscan.fit(X)
# 이상치 제거
mask = np.zeros(len(X), dtype=bool)
mask[dbscan.labels_ == -1] = True
X_cleaned = X[~mask]
Cook Distance나 DBSCAN 말고도, 의사결정트리를 이용한 방법이나, LOF를 이용한 방법 등이 있다. 다시 한번 명심할 것은 이상치로 구해진 값들이, 실제 모델링에서 제거해도 되는 값들인지 꼭 확인해보아야한다.
'Data Science' 카테고리의 다른 글
| DTW(Dynamic Time Warping) (1) | 2023.06.02 |
|---|---|
| PCA(Principal Component Analysis) (1) | 2023.05.04 |
| 이상치(Outlier) 제거 방법(1) - 통계적 방법 (5) | 2023.03.19 |







