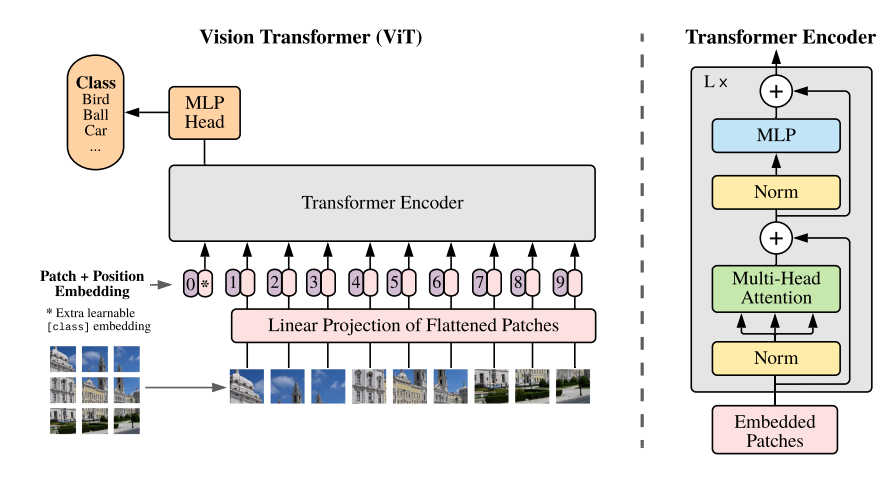
반응형
EfficientViT 배경 설명
- EfficientViT는 2023년 발표된 논문이다.
- ViT의 memory 효율성을 개선하기 위해, 샌드위치 구조의 레이아웃과 cascaded group attention을 도입한 EfficientViT model을 제안하였다.
- model 속도와 accuracy가 매우 좋다.
Abstract
- ViT는 성능이 좋지만, 연산 비용이 너무 커서, 실사용에 문제가 있다.
- 이 논문에서는 EfficientViT라는 빠른 속도의 ViT 모델을 소개한다.
- 기존 transformer 구조의 모델들이 memory를 효과적으로 사용하지 못하는 MHSA(Multi-Head Self-Attention)의 tensor reshaping이나 element-wise function으로 인해 제약이 있음을 발견했고, FFN 층들 사이에 MHSA를 배치하는 샌드위치 구조를 구성하여 memory 사용량을 줄였다.
- 또한, head들의 attention map들 간에 비슷한 부분을 공유하여, 연산적으로 불필요한 부분이 많다는 것을 발견하였다. 이를 해결하기 위해, cascadede group attention module이라는 feature를 각기 다른 split들로 attention head를 통과시키는 구조를 제안했다. 이로 인해, 단순 연산의 단순함뿐 아니라, attention의 다양성도 향상했다.
- 실험을 통해, EfficientVit는 기존 efficient model들에 비해 더 빠른 속도에서 좋은 성능을 보임을 증명했다.
Introduction
[배경]
- 기존 ViT model들은 computer vision 분야에서 좋은 성능을 보여주었지만, 성능 증가에 다라 model size 증가와 연산 overhead 증가로 인해, 실시간을 요하는 상황에서 사용하기 불안정하다.
- 이를 해결하기 위해, 다양한 ViT 경량화 model들이 나왔지만, model parameter와 Flop을 줄이는 방식을 사용했기에 속도에 대한 객관적 측정이 될 수 없고, 실제 inference throunput을 반영하지 못한다. (속도 향상이 model size 줄이는 것에 기인했는지, 방법에 기인했는지 객관적 판단 불가)
[논문-Analysis]
- 이를 해결하기 위해, 논문에서는 ViT를 빠르게 하기 위해 근본적으로 ViT를 어떻게 설계해야할지를 연구하였다.
- ViT inference speed에 영향을 미치는 3가지 요인인, memory access, computation redundancy, parameter usage 측면에서 살펴봤고, 그중, memory bound의 영향이 큰 것을 발견했다.
- 즉, memory 접근이 GPU/CPU의 연산 활용을 막고, 속도에 부정적 영향을 미침을 발견했다.
- memory가 비효율적으로 활용되는 연산들은 주로 multi-head self attention(MHSA)의 tensor reshaping과 element-wise function 연산에서 나타났다.
- 논문에서는 MHSA와 FFN의 비율을 적절히 조정하여 성능을 유지하면서 memory 접근을 크게 줄였다.
- 또한, 몇개의 attention head들이 서로 선형 관계를 갖기 때문에 attetion map에 불필요하다는 것을 발견하였다.
- 이 현상을 각 head에 다양한 feature를 제공하는 방식을 활용하여, 완화시키고 연산 효율성도 가져갈 수 있다.
- 추가적으로 parameter 효율성을 향상하기 위해, structured pruning을 이용하여, 불필요한 parameter를 줄였다.
[EfficientViT]
- 논문에서는 앞선 연구를 바탕으로 "EfficientViT"를 제안한다.
- 특히, 샌드위치 구조의 레이아웃으로 모델을 만들어, MHSA와 FFN 사이에 하나의 memory bound만 두게 하여, 연산 속도를 향상했다.
- 또한, 새로운 cascaded group atention(CGA) 모듈을 제안하여, 연산 효율성을 향상했다.
- CGA의 핵심 아이디어는 head에 각기 다른 feature를 input으로 준다는 것이다. (즉, Head 들간의 선형적 관계 등의 중복된 feature들이 연산에 비효율적이기 때문에 각기 다른 feature를 보도록 조정하겠다.)
- 마지막으로, network의 중요한 부분에 channel을 늘리는 등 parameter를 재조정하여, parameter 효율성을 향상한다.
[실험]
- 기존 CNN과 ViT 기반의 lightweight 모델에 비해 빠르면서 성능이 좋다.
ViT 속도 연구
- ViT 효율성을 향상하기 위해, 3가지 측면(1.memory access 2.computation redundancy 3.parameter usage)에서 관찰하였다.
Memory Efficiency
- Memory 접근으로 인한 ovehead는 model 속도에 매우 주요한 요인이다.
- transformer의 연산 중, tensor reshaping, element-wise addition, normalization 등이 memory unit 사이들의 접근을 요해서, 시간이 오래 걸리게 된다.
- 이 연산들을 조금 더 간단하게 바꾸기 위한 연구들이 있었으나, (softmax self-attention 간략화, sparse attention, low-rank approximation) 대게 성능 하락이 존재하고, 속도 향상에 한계가 있었다.
- 이 논문에서는 memory access를 줄이기 위해, memory-inefficient layer를 줄이는 방법을 사용한다.
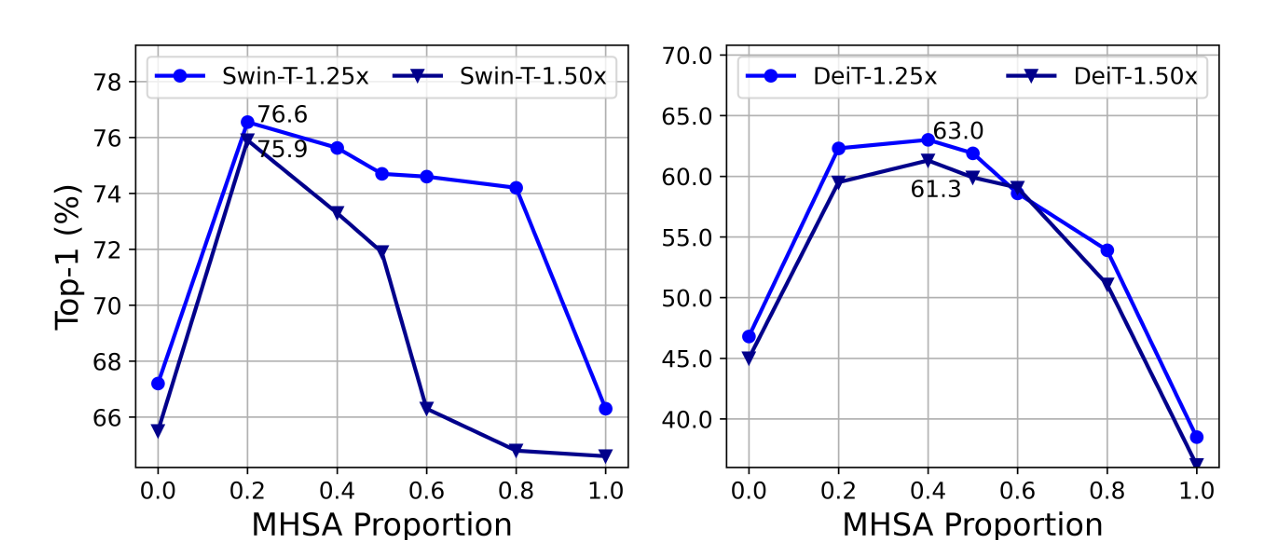
- 최근 연구들에서 memory에 비효율적인 부분은 FFN보다 MSHA에 주로 존재한다고 하였다. 하지만, 기존 ViT 구조에서는 두 layer들이 동일한 수를 유지하고 있다.
- 논문에서 Swin-T, DeiT-T로 실험해 보았을 때, MSHA의 비율을 20~40%로 줄였을 때, 좋은 성능이 나오고, 속도로 각각 1.25배, 1.5배로 빨라졌음을 확인했다. (아래 그래프 참고)
- 즉, MSHA의 비율을 줄이는 것이 모델 성능과 속도 측면에서 모두 유리했다.
Computation Efficiency
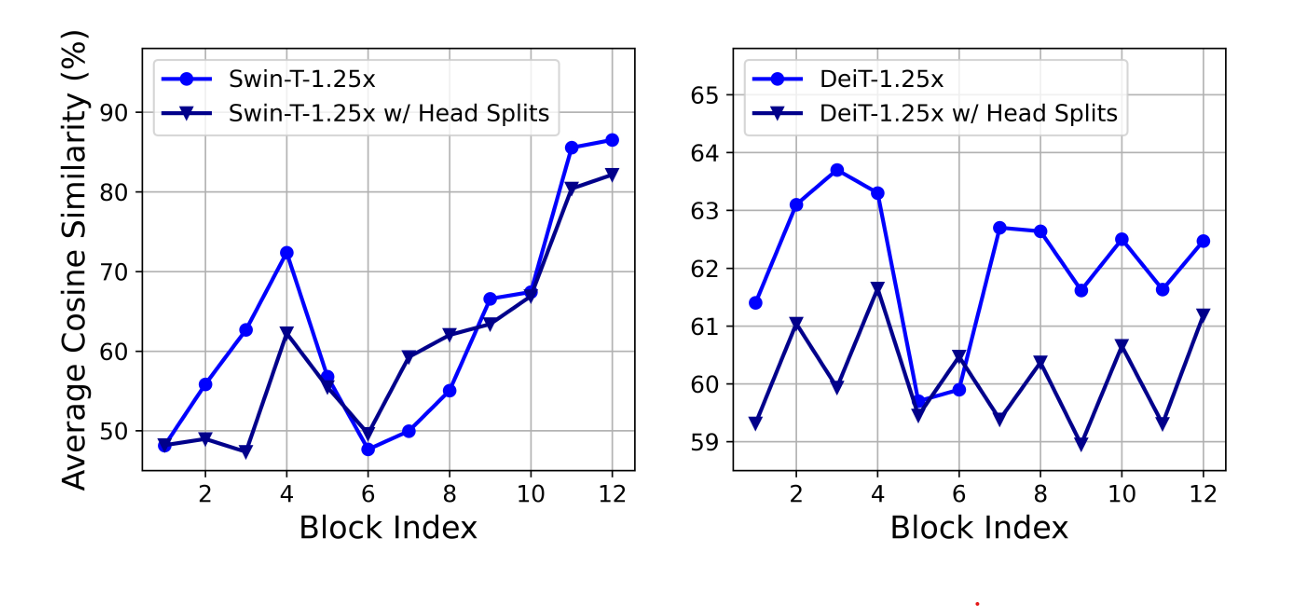
- MHSA에서 attention map은 연산이 비싸지만, 그중 일부들은 꼭 필요 없다는 것이 알려져 있다.
- attention 간의 similarity를 재보았을 때, 매우 높은 similarity를 보였다.
- 이것은 각 head들이 동일 feature에 대해서 비슷한 projection을 하기 때문에, 불필요한 연산들이 존재한다는 것을 의미한다.
- 각 head들이 다른 pattern을 보이게 하기 위해, 각 head에 feature의 부분 부분을 쪼개어 각기 다른 feauture를 처리하도록 하는 방법을 사용했다. 이것은 group convolution과 비슷한 개념이다.
Parameter Efficiency
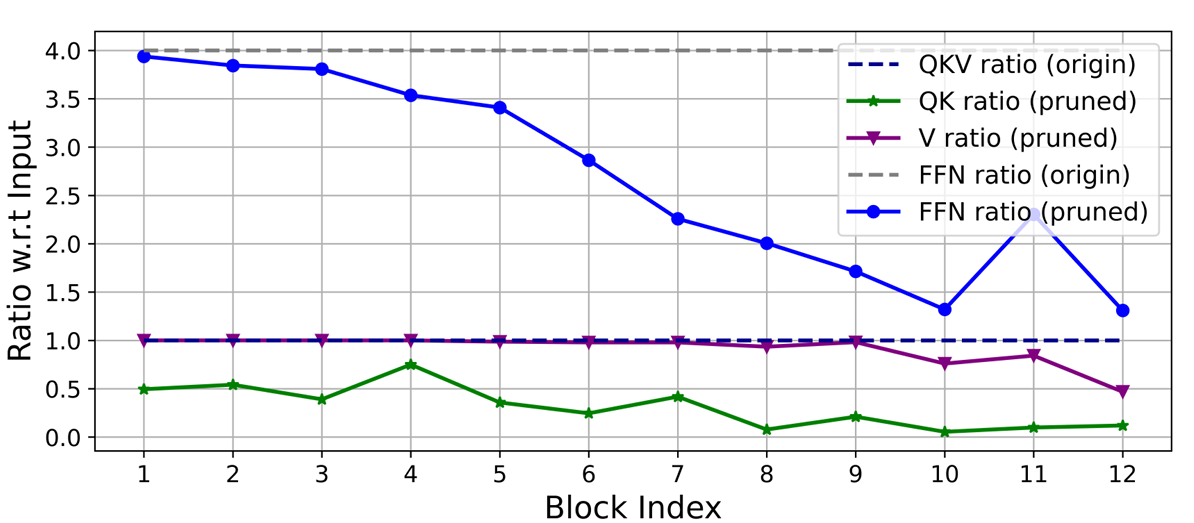
- ViT는 NLP의 Transformer 구조를 그대로 가져왔기 때문에, Q, K, V의 구조를 따르고, FFN의 확장 비율을 4로 설정해 놓았다.
- Lightweight model에서는 이러한 구조를 재설계하는 방식을 따르는데, 이 논문에서도 Talylor structured pruning을 사용하여 중요 parameter만 남기도록 하였다.
- 이 방법은 gradient와 weight의 곱을 channel 중요도로 정의하여, 중요하지 않은 channel을 제거하고, 가장 중요한 channel을 유지하는 방법을 사용한다.
- 연구를 통해, 2가지 사실을 알 수 있는데, 첫 번째로, 첫 2 stage에서는 더 많은 dimension을 유지하지만, 마지막 단계에서는 훨씬 적은 dimension이 유진 된다. 두 번째로, Q, K 및 FFN dimension은 크게 축소되지만, V dimension은 거의 유지되고, 마지막 몇 개의 block에서만 감소한다.
- 이를 통해, 1) 기존 channel 구성 방식(FFN 확장 비율 :4)은 마지막 몇 개의 block에서 많은 중복을 초래한다. 2) Q, K는 V에 비해, 훨씬 많은 중복이 존재하고, V는 상대적으로 더 큰 dimension을 선호한다. 는 점을 유추할 수 있다.
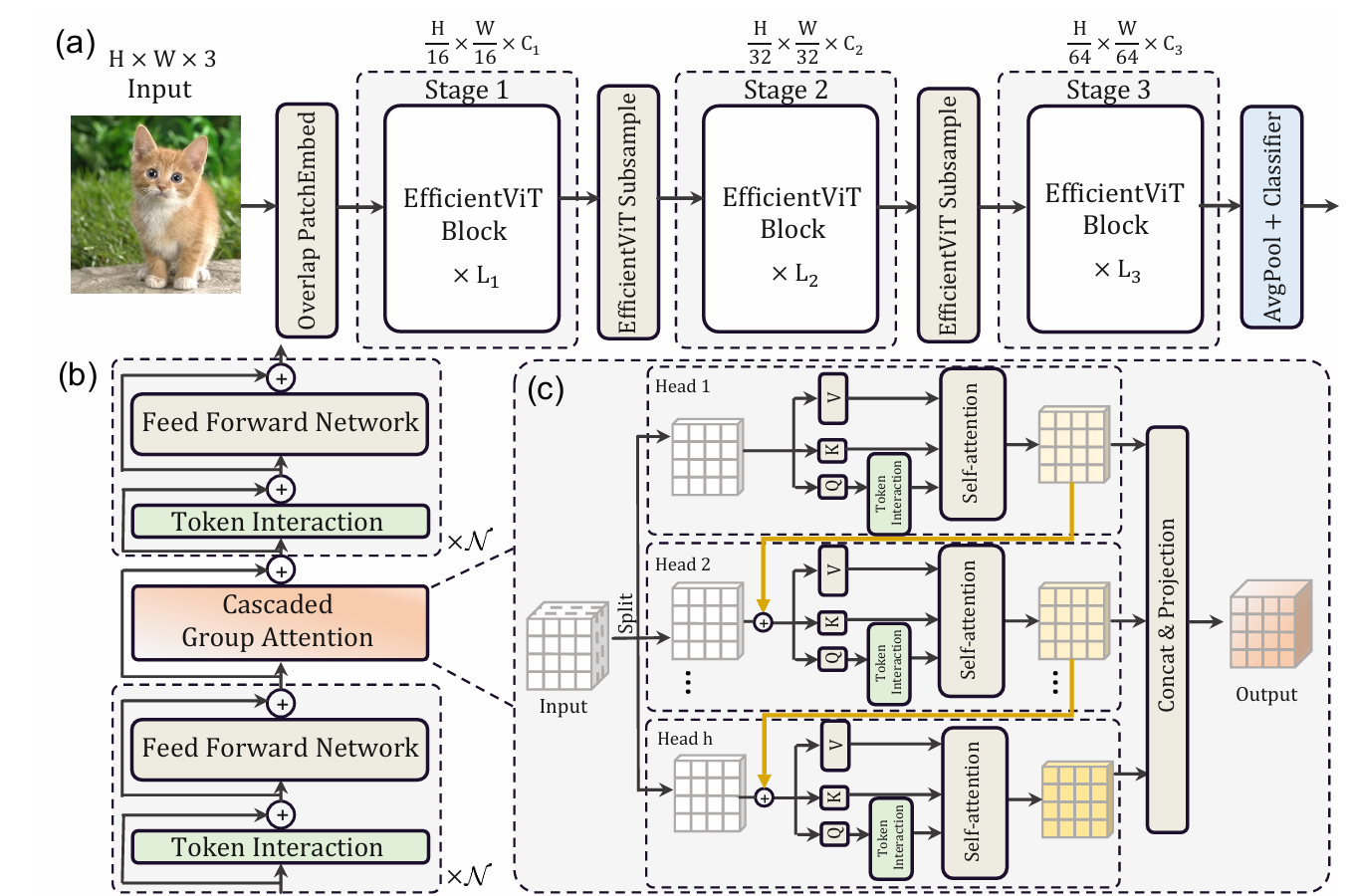
EfficinetViT
EfficinetViT Building Block
- 아래 그림처럼 EfficientViT는 memory 효율적인 샌드위치 구조의 layout과 cascaded group attention을 사용했다.
[Sandwich Layout]
- spatial mixing을 위해 self-attention layer를 중간에 두고, 이를 FFN layer가 양쪽에서 감싸는 형태로 구성하는 구조이다.
- 이 설계로 인해, model 내, self-attention layer로 인한 memory 사용 및 처리 시간을 줄이고, FFN layer를 더 많이 활용하여 , 다양한 channel 간 연결을 효과적으로 수행되도록 한다.
[Cascaded Group Attention]
- MHSA에서 attention head의 중복성은 연산 효율성을 떨어뜨린다.
- 이를 해결하기 위해, group convolution에서 영감 받아, ViT용 Cascaded Group Attentin을 제안한다.
- 이는 각 head에 full feature를 나눈 서로 다른 부분을 입력으로 사용하여, attention 연산을 각 head에 분산시킨다.
- CGA는 각 head의 입력에 더 풍부한 정볼르 포함하도록, Q, K, V layer를 개선한다.
- 각 head의 출력이 다음 head의 입력에 추가되어, feaure의 representation이 점점 향상된다.
- 추가적으로 Q projection 이후에 새로운 token interaction layer를 추가하여, self-attention이 local과 global 관계를 동시에 잡을 수 있도록 한다.
- 이런 cascaded 방식은 2가지의 장점이 있다. 1) attention map의 다양성 향상 2) network 깊이 증가
[Parameter Reallocation]
- parameter 효율성 증가를 위해, network의 parameter를 중요한 부분의 channel은 더 넓게, 안 중요한 부분은 더 좁게 만드는 재배치를 진행하였다.
- Q, K는 앞선 연구를 바탕으로 작은 channel만 할당하였고, V에 대해선 느 input embedding과 동일 dimension을 유지하도록 하였다.
- 또한, FFN의 parameter 중복성을 고려해 기존 확장비율 4에서 2로 조정하였다.
- 이로 인해, 중요 정보는 유지하면서 불필요 parameter를 줄여 model 효율성을 향상했다.
EfficinetViT Network Architecture
- model은 크게 3가지 단계로 구성되었다. 각 단계는 앞선 EfficientViT Block들로 구성되어 있고, 각 subsampling layer에서 token 개수가 4배 감소한다.
- 효과적인 subsampling을 위해, sandwich 구조의 subsampling block을 제안하였다. 정보 손실을 최소화하기 위해, ㄴself-attention layer를 inverted residual block으로 대체하였다.
- EfficientViT는 Layer Normalization 대신, Batch Normalization을 사용했다. (실행 시간 측면에서 유리)
- 속도를 위해, GELU, HardSwish 대신 RELU를 사용했다.
Experiments
- ImageNet-1K classification에서 기존 lightweight model들에 비해, 빠른 속도에서 더 좋은 성능을 보였다.

Reference
Liu, X., Peng, H., Zheng, N., Yang, Y., Hu, H., & Yuan, Y. (2023). Efficientvit: Memory efficient vision transformer with cascaded group attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14420-14430).
'Computer Vision' 카테고리의 다른 글
| MobileViT v2 논문 리뷰 (34) | 2024.01.08 |
|---|---|
| Fine-tuning Image Transformers using Learnable Memory 논문 리뷰 (21) | 2023.12.12 |
| MobileViT 논문 리뷰 (57) | 2023.12.07 |
| DETR : End-to-End Object Detection with Transformers 논문 리뷰 (47) | 2023.11.07 |
| DeepVit: Towards Deeper Vision Transformer 논문 리뷰 (1) | 2023.10.11 |