반응형
Hierarchical Clustering
Hierarchical Clustering은 사실, 데이터 분석 및 알고리즘에서 많이 사용해보지 않은 알고리즘이다. Hierarchical Clustering의 원리와 특징등을 조금 더 공부해보고 싶었다.
Hierarchical Clustering 이란?
- Hierarchical Clustering (계층적 군집화)는 데이터 포인트들을 거리나 유사도 기반으로 계층적으로 묶어나가는 군집화의 방법이다.
- Hierarchical Clustering의 결과는 보통 Dendrogram 형태로 표현하여 쉽게 확인 가능하다.
- Hierarchical Clustering은 계층의 구조를 시각적으로 파악 가능하여, 크지 않은 데이터셋들의 구조 분석이나 증빙, 이상치를 정의하는 일등에 활용된다.

Hierarchical Clustering의 특징
장점
- Hierarchical Clustering에서의 Cluster의 개수는 계층 구조를 보고, 조정 가능하기 때문에, 유연성이 높다. (미리 Cluster 개수를 정해놓을 필요가 없음)
- Hierarchical Clustering은 Clustering된 과정과 결과를 한눈에 확인 가능하기 때문에, 각 Cluster의 크기와 Cluster 간의 관계를 파악 가능하다. (Cluster 간 비교 분석에 용이)
- Hierarchical Clustering 수행 시, 이상치는 다른 Cluster와 계층적으로 별도 분리되어 있을 가능성이 크기 때문에, 이상치 제거에 활용 가능하다.
단점
- Hierarchical Clustering의 계산 복잡도가 큰 편이다. 특히, 모든 데이터셋 간의 거리를 비교해야하기 때문에, 데이터셋의 크기가 클수록 계산복잡도가 늘어난다. (일반적으로 O(N³))
- Hierarchical Clustering은 데이터 포인트 전체를 고려하기 때문에, 데이터의 삭제나 추가, 변경에 대해 민감하다.
일반적으로, Hierarchical Clustering은 연산 시간이 크다는 단점을 가지고 있어서, 대용량 데이터의 분석에 그대로 적용하는데는 한계가 있다. 하지만, 계층 시각화 및 군집 간 관계 파악등이 가능하기 때문에, 초기 데이터 분석 시, 적은 양의 데이터로 사용하기 좋은 기법이다.
Hierarchical Clustering 알고리즘
Hierarchical Clustering은 각 데이터 포인트 간의 거리나 유사도를 계산하여, 작은 단위부터의 Clustering을 진행하면서, 전체 데이터 포인트가 하나의 Cluster를 구성할 때까지 Clustering을 반복적으로 진행하는 방식을 사용한다.
1. 각 데이터 포인트를 개별 Cluster로 고려
- 총 데이터가 N개 존재한다고 할 때, 각 포인트 1개씩을 가지고 있는 N개 Cluster를 형성한다.
2. Cluster 간 Distance Matrix를 계산
- 각 Cluster 간 거리 or 유사도를 계산한다. Cluster 간의 거리나 유사도를 계산하는 방법은 많지만, 보통 Euclidean Distance를 사용한다.
- N개 Cluster가 서로 간의 Distaince를 계산하기 때문에, distance matrix를 구하기 위해 N(N-1)/2번 최소 연산이 필요하다.
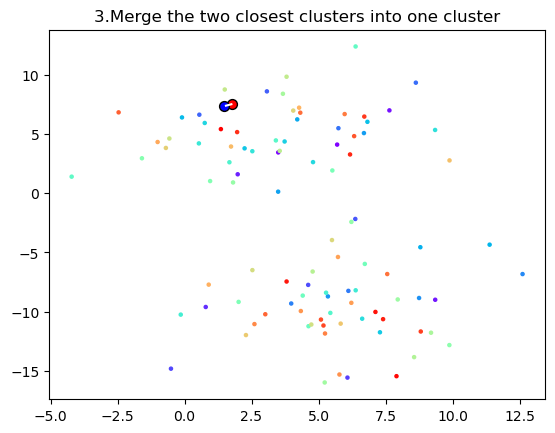
3. 가장 비슷한 2개의 Cluster를 하나의 Cluster로 Merge
- 앞서 구한, Distance Matrix를 기반으로 가장 유사한 or 거리가 가까운 Cluster들을 하나의 Cluster로 연결한다. 즉, 가장 가까운 거리에 있는 두 데이터 포인트를 묶어서 Cluster를 형성한다.
- N개 Cluster에서 N-1개 Cluster가 된다.
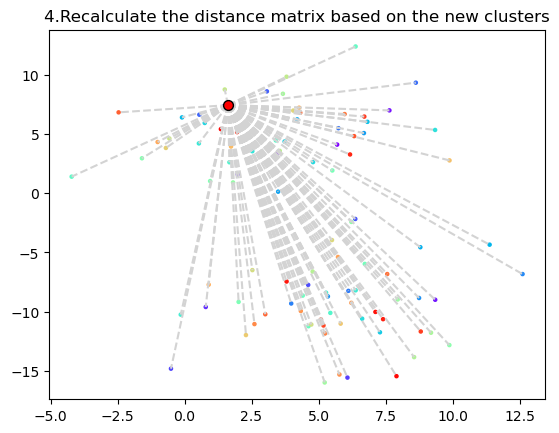
4. 변경된 Cluster를 고려한 Distance Matrix 재계산
- 새로운 Cluster가 생성되었기 때문에, Distance Matrix의 업데이트가 필요하다.
- 새로 구성된 Cluster는 2개의 데이터 포인트를 가지고 있기 때문에, Distance Matrix를 어떻게 구할 것인지 정의가 필요하다.
- Distance Matrix를 구하는 방법은 아래와 같다.
- Single Linkage : 새로운 Cluster와 나머지 Cluster 간 거리는 한 Cluster 내의 데이터 포인트 들과 다른 Cluster 내의 데이터 포인트 들 사이 거리 중 가장 가까운 거리로 정의
- Complete Linkage : 새로운 Cluster와 나머지 Cluster 간 거리는 한 Cluster 내의 데이터 포인트 들과 다른 Cluster 내의 데이터 포인트 들 사이 거리 중 가장 먼 거리로 정의
- Average Linkage : 새로운 Cluster와 나머지 Cluster 간 거리는 한 Cluster 내의 데이터 포인트 들과 다른 Cluster 내의 데이터 포인트 들 사이 거리들의 평균으로 정의
- Ward's Method : Cluster 내 데이터 포인트의 평균으로 중심점을 구하고, 각 Cluster의 중심점 기준으로 distance를 구함. 두 Cluster를 합친 후, 새로운 Cluster 내의 SSW(Sum of Squares Within)가 최소화되도록, 거리를 계산함. (d_i, d_j : Cluster 중심 점과 각 데이터 포인트 간 거리의 합, n_i, n_j : Cluster 데이터 포인트 갯수, p: 전체 데이터 갯수, d_ij: Cluster i와 j 사이 거리)

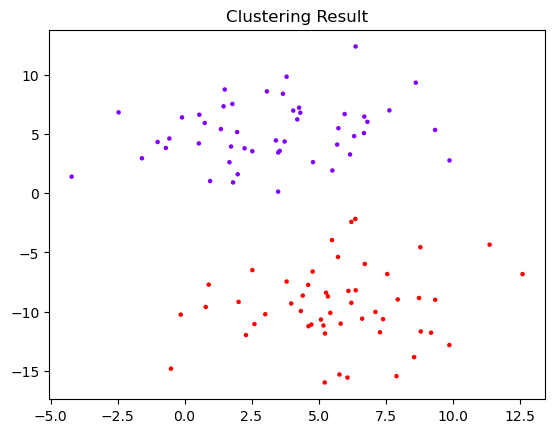
5. 3~4 단계를 Cluster가 1개로 합쳐질 때까지 반복
- Cluster Merge와 distance matrix 계산을 N-1번 반복하면, Cluster는 1개만 남는다.
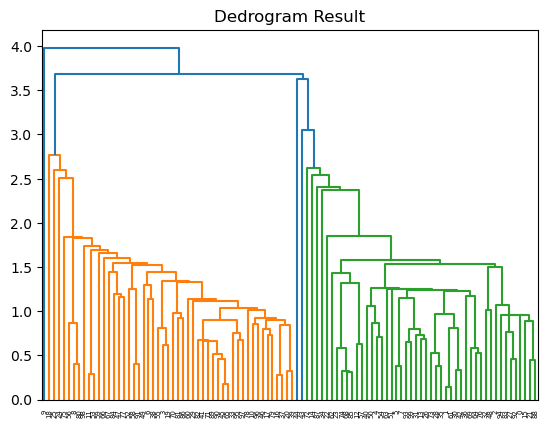
6. Dendrogram 시각화
- 각 Cluster Merge 단계들을 Dendrogram으로 나타내서, 계층 구조를 확인한다.



Hierarchical Clustering Python 구현
- 단순 Clustering 결과를 보기 위해서는 scikit-learn의 "AgglomerativeClustering"를 사용하면 쉽게 사용 가능하다.
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_blobs
if __name__ == '__main__':
X, y = make_blobs(n_samples=20, centers=2, random_state=10, cluster_std=2)
model = AgglomerativeClustering(linkage='average')
model.fit(X) # 데이터 Training
model.fit_predict(X) # 데이터 Predict
model.labels_ # Training sample 할당된 Cluster Label 표시
model.n_leaves_ # 계층 Cluster leaf node 수- AgglomerativeClustering의 매개변수는 다음과 같다.
- n_clusters : cluster 갯수 지정, (미지정 시, 적당한 Cluster 개수로 나눠줌)
- linkage : cluster 간 distance 연산에 사용하는 방법 ('ward', 'single', 'complete', 'average' 선택 가능, default는 'ward')
- affinity : cluster 간 distance 연산에 사용하는 식 ('euclidean','manhattan', 'cosine', 'precomputed' 선택 가능, default는 'euclidean')
- Dendrogram을 보기 위해서는 scikit-learn의 pdist와 linkage, dendrogram을 사용해야 한다.
from scipy.spatial.distance import pdist
from scipy.cluster.hierarchy import linkage, dendrogram
if __name__ == '__main__':
X, y = make_blobs(n_samples=20, centers=2, random_state=10, cluster_std=2)
distance_matrix = pdist(X) # distance matrix 계산
linkage_matrix = linkage(distance_matrix, method='single') # linkage 단계를 matrix화 함
dendrogram(linkage_matrix)- pdist는 distance matrix를 1D 형식으로 구하는 함수로 자기 자신과 중복을 제거한 N(N-1)/2 개의 값이 나온다. (만약 matrix의 각 데이터 포인트 값을 알고 싶다면, cdist를 사용하면 된다. 다만, linkage 인자는 cdist를 넣어줘야 한다.)
- pidst 함수에서 'metric' 매개변수로 distance 계산 방식을 바꿔줄 수 있다.
- linkage 함수에서 'method' 매개변수로 cluster 간 거리 측정 방식을 바꿔줄 수 있다. ('single', 'complete', 'average', 'ward')
- likage matrix는 N X 4의 matrix로 표시되고, 각 칼럼은 다음과 같은 의미를 가지고 있다.
- 1 열: 첫 번째 Cluster 번호
- 2 열: 두 번째 Cluster 번호
- 3 열: 두 Cluster 합쳤을 때의 거리 or 유사도
- 4 열: 새로운 Cluster 구성하는 데이터 포인트의 개수
'머신러닝' 카테고리의 다른 글
| Logistic Regression(로지스틱 회귀 분석(1)-이진 분류) (1) | 2023.04.17 |
|---|---|
| Linear Regression(선형 회귀) (1) | 2023.03.23 |
| K-means Clustering (1) | 2023.03.13 |
| GMM(가우시안 혼합 모델) Clustering (1) | 2023.03.10 |
| DBSCAN(밀도 기반 클러스터링) (5) | 2023.03.08 |
























