DeBERTa 배경 설명
- DeBERTa는 2020년 Microsoft에서 ICLR 2021에 낸, BERT의 성능을 개선한 논문이다.
- 기존 BERT를 개선한 논문들은 엔지니어링적 개선에 가까웠는데, 이 논문은 새로운 방법들을 제시해서, BERT의 성능을 향상했다.
- ICLR에 발표된 논문인만큼, 실험과 설명이 자세하게 적혀있어, 직접 읽어보는 것을 추천한다.

Abstract
- 이 논문에서는 DeBERTa(Decoding-enhanced BERT with disentangled attention)이라는 새로운 모델을 제시한다.
- 이 모델은 2가지 새로운 방법을 사용하여, BERT, RoBERTa보다 높은 성능을 보인다.
- disentangled attention : 각 word들은 content와 position vector로 표현되고, 그들의 contents와 상대적 위치에 따라, words들 간에 attention을 구한다.
- enhanced mask decoder : 개선된 mask decoder로 decoding layer의 절대 위치를 포함하여, masking token을 예측한다.
- 추가적으로, 새로운 virtual adversarial trainin이 model의 generalization을 향상하기 위해 사용된다.
- 이를 통해, NLU(자연어 이해) 뿐 아니라, NLG(자연어 생성)에서도 기존 모델인 BERT, RoBERTa에 비해 좋은 성능을 보인다.
Introduction
- Transformer는 문장 내의 각 단어가 미치는 영향을 self-attention으로 연산하여, 병렬 수행이 가능하도록 하였다.
- 이 논문에서는 distentangled attention과 enhanced mask decoder를 사용하여, BERT의 성능을 개선한, DeBERTa를 소개한다.
[Disentangled attention]
- 기존 positional 정보와 content 정보의 합으로 표현되던 BERT의 embedding과 다르게, DeBERTa에서는 content와 postion vector를 따로 encode 한다.
- word 사이에 attention weights는 그들의 contents와 상대적 위치를 고려하여, disentangled matrics를 통해 구해진다.
- 이것은 attention이 contents 뿐 아니라, 그 사이의 상대적 위치에 의존한다는 것에서 비롯되었다.
[Enhanced mask decoder]
- DeBERTa도 BERT와 동일하게 masked language modeling을 이용해서 학습한다.
- Disentangled 단계에서 이미 상대적 위치는 고려했지만, prediction에서 매우 중요한 각 단어의 절대적 위치는 고려하지 못한다. (절대적 위치는 문장 내에서 역할을 의미할 수 있다.)
- DeBERTa에서는 각 단어의 절대적 위치 정보를 softmax 단 바로직전에 합쳐준다.
- 추가적으로, 이 논문에서는 fine-tuning 단계에서 새로운 virtual adversarial training 방법을 제시한다. 이 방법은 model의 generalization을 향상한다.
Background
[Transformer]
- Transformer에 대한 설명은 아래 참조
- 기본 Transformer에서는 word의 위치정보가 부족하다. 이를 해결하기 위해, 문장 내 단어의 상대적 위치와 절대적 위치를 고려하는 방법들이 나왔지만, 일반적으로 상대적 위치를 사용하는 것이 효과적으로 알려져 있다.
- 이 논문은 각 단어가 word content와 position의 2개의 독립적인 vector를 사용하고, attention weight를 각 vector의 disentangled metrics를 사용해서 구한다는 점에서 기존 방법들과 차이점이 있다.
2023.05.08 - [NLP 논문] - Transformer (Attention Is All You Need) - (1) 리뷰
Transformer (Attention Is All You Need) - (1) 리뷰
Transformer 배경 설명 Transformer는 Google Brain이 2017년 "Attention is All You Need"라는 논문에서 제안된 딥러닝 모델이다. Transformer는 기존 자연어 처리 분야에서 주로 사용되던 RNN, LSTM 같은 순환 신경망 모
devhwi.tistory.com
[Masked Language Model]
- 자연어 모델에서는 BERT 이후로 Masked Language Modeling을 많이 사용한다.
- Masked Language Modeling에서는 model parameter θ를 학습하기 위해, 다음의 objective를 사용한다.

DeBERTa
[disentangled attention]
disentangled attention 식을 만들기 위해, 몇 가지를 설명한다. 논문 내에는 따로 구분 짓지 않았지만, 설명 편의를 위해 임의로 3가지 part로 나눴다.
1. Vector 구성 요소
- 문장 내 i번째 token은 다음과 같은 두 개의 vector로 구성된다.
- i번째 contents vector: \(H_i\)
- i번째 token에서 j번째 token과의 상대적 position : \(P_{i|j}\)
- i번째 token과 j번째 token 간의 attention score는 다음과 같이 계산된다.

→ 위의 수식은 4개의 component로 분리되는데, 왼쪽부터 각각, "content-to-content", "content-to-position", "position-to-content", "position-to-position"이다.
- 이 논문이 지적하고 있는 것은 과거 논문들에서는 attention의 4가지 component 중, "content-to-content"와 "content-to_position"만 사용하고 있다는 것이다. (content vecotor에 position을 더해서 만들었기에)
- 특히, 문장 내에서 두 단어 간의 상관관계를 고려할때, 단순 contents만 보는 것이 아니라, 두 단어간의 상대적 위치도 매우 중요하기 때문에 "position-to-contents"와 "contents-to-position"을 모두 봐야 한다.
- 수식 내용 중, position vector가 상대적 위치를 기반으로 만들어졌기 때문에, "position-to-position"은 추가적인 정보를 주지 못하므로, 수식에서 삭제한다.
2. Self-attention operation
- self-attention은 아래와 같은 수식을 통해 구해진다. Output hidden vector인 \(H_o\)를 구하기 위해, Query(Q)와 Key(K)를 통해 Attention(A)을 구하고, Attention을 Normalize 한 후 Value(V)에 곱한다.

3. 상대적 위치
- 이 논문에서는 상대적 위치를 아래와 같이 계산한다.
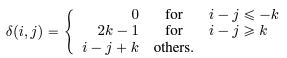
→ k는 maximum relative distance. 위의 거리 식을 생각해 보면, 현재 token의 앞쪽에 위치한 token은 distance가 0으로 주의 깊게 보겠다, 뒤쪽에 위치한 token 중, k 이내는 가까울수록 고려 많이 하겠다, 그 외에는 조금만 고려하겠다는 뜻으로 이해된다.
- 위의 1,2,3번을 종합하면, disentangled attention은 1.attention은 3개 component로 구성되었고, 2. self-attention 기반, 3. 상대적 거리를 고려하는 attention이다.
- 최종적으로 output hidden vector는 아래와 같이 구해진다.
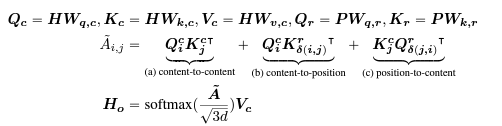
→ 주의해야 할 점은, "position-to-content"에 \(\delta(j, i)\)가 사용되었다는 점인데, 이것은 "position-to-content"를 구할 때, 사용되는 content가 j번째 content이기 때문이다.
[enhanced mask decoder]
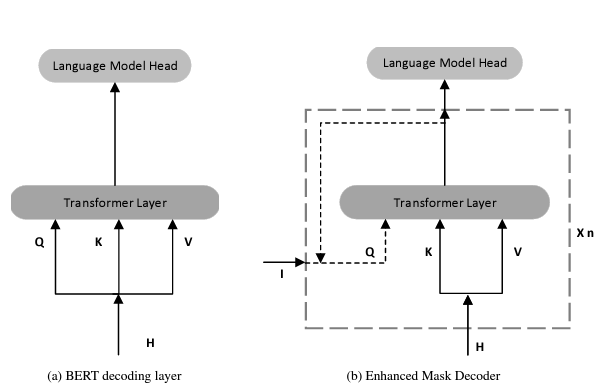
- disentangled attention에서 relative position은 고려되었지만, absolute position은 실제 mask-prediction에 중요함에도 불구하고, 고려되지 않았다.
- 특히, 뉘앙스 같은 것은 absolute position 정보가 중요하다.
- DeBERTa에서는 모든 Transformation layer들의 직후, softmax layer 전단에 absoulte position 정보를 넣어주었다.
- 이를 통해, Transformer가 elative position을 우선 고려하되, absolute position 정보도 보완 정보로 사용할 수 있게 하였다.
- 이러한 모델을 Enhanced Mask Decoder(EMD)라고 부른다.
- BERT 방식(input 정보에 absolute position 정보를 넣는 것)에 비해 성능이 좋다.
Scale Invariant fine-tuning
- Layer Noramlization 기법에 영감을 받아, SIFT 알고리즘을 사용하였다.
- SIFT는 word embedding vector를 확률 vector로 normalization 하고, normalize 된 word embedding에 preturbation을 적용한다.
- 이로 인해, fine-tuend model의 성능이 상당히 향상되었다.
Experiment
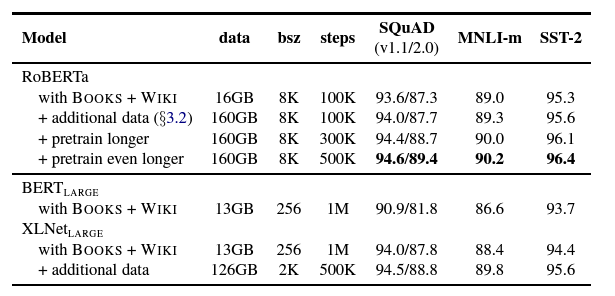
- Large model : GLUE에서 다른 large model에 비해 좋은 성능을 보였다.
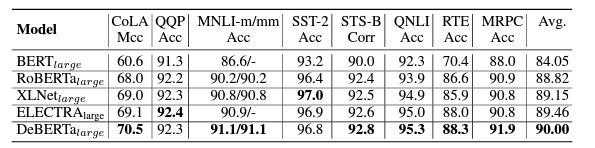
- Base model : Base 모델에서도 좋은 성능을 보였다.

ETC
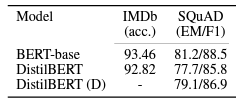
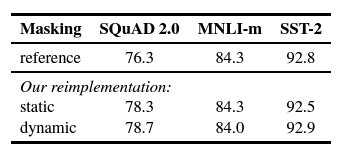
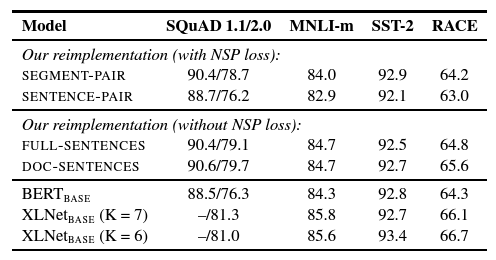
- 사용한 데이터 셋
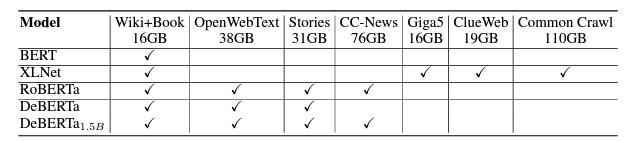
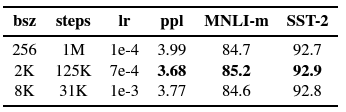
- model 학습을 위한 paramter
- RoBERTa와 attention visualization 비교

→ RoBERTa는 diagonal line이 두드러지지만, DeBERTa는 그렇지 않다. 이것은 EMD의 영향인 것으로 확인된다.(DeBERTa가 다른 단어를 골고루 본다는 뜻인 것 같다.)
→ RoBERTa는 vertical line이 2줄 존재하는데, 하나는 special token(CLS)등 때문이고, 하나는 high frequency token(예시: a, the) 때문이다. DeBERTa는 special token 영역의 1줄만 존재한다.(특정 단어에 무조건 의존하는 현상이 적다는 것을 말하는 것 같다.)
Reference
He, Pengcheng, et al. "Deberta: Decoding-enhanced bert with disentangled attention." arXiv preprint arXiv:2006.03654 (2020).
총평
- 실험이 정말 많아서, 많은 생각을 할 수 있게 만든 논문이다.
- BERT 관련 논문들을 계속 읽어오고 있는데, 모델 단의 개선 아이디어는 처음인 것 같아서, 재밌었다.
DeBERTa 관련 git : https://github.com/microsoft/DeBERTa
'NLP 논문' 카테고리의 다른 글
| PaLM(Scaling Language Modeling with Pathways) 논문 리뷰 (1) | 2023.06.29 |
|---|---|
| GPT-3 (Language Models are Few-Shot Learners) 논문 리뷰 (5) | 2023.06.12 |
| DistilBERT(a distilled version of BERT) 논문 리뷰 (4) | 2023.06.04 |
| RoBERTa (A Robustly Optimized BERT Pretraining Approach) 논문 리뷰 (1) | 2023.06.03 |
| GPT-2 (Language Models are Unsupervised Multitask Learners) 논문 리뷰 (1) | 2023.05.27 |