
GPT-3 배경 설명
- GPT-3은 요즘 많이 사용하는 ChatGPT의 근간이 된 논문으로, 2020년 OpenAI에서 NIPS에 발표한 논문이다.
- Language Model의 parameter가 꾸준히 늘어가는 추세였는데, GPT-3에서는 기존의 가장 큰 모델보다 거의 10배 정도의 많은 parameter를 넣을 정도로 큰 모델을 사용하였다.
- Model scaling-up을 통해 few-shot에서도 Task-Specific 한 기존의 finetuning 모델들의 성능에 필적하는 성능을 보여주었다. (이 시도가 현재 ChatGPT를 만든 것 같다.)
Abstract
- 최근 NLP task에서 large corpus의 pre-training을 기반으로한 언어모델들이 큰 효과를 내고 있다.
- 하지만, 대부분의 모델은 task-agnostic의 재학습이 필요하고, 이 과정에서 task에 맞는 수많은 학습 데이터들이 필요하다.
- 이 논문에서는 언어모델의 사이즈를 키워서, 현재 task-agnostic SOTA 모델들의 성능에 필적할수 있을 정도로 few-shot 모델 성능을 향상했다.
- 특히, 175 billion parameter로 구성된 GPT-3을 few-shot으로 학습하였는데, 다양한 NLP 분야에서 좋은 성능을 보였다.
- 추가적으로 GPT-3은 인간이 작성한 기사와 구분하기 어려운 뉴스 샘플등을 생성할 수 있다는 사실을 발견하였고, 이 발견과 사회적 영향에 대해 논의한다.
Introduction
[문제]
- 최근 NLP 분야에서의 pre-trained language model의 트렌드는 다양하고 많은 분야에서 큰 향상을 일으켰지만, 이러한 모델들은 task-agnostic 한 방식을 채택하고 있어, 원하는 task에 대한 수많은 데이터셋과 fine-tuning 과정을 필요로 한다.
- 이러한 방식은 아래의 문제가 있다.
- 실용적 관점에서 모든 새로운 task에 대해서 labeling 된 데이터가 필요하여, 언어모델의 확장성을 제한한다. 각 task 학습을 위한 dataset이 필요한데, 그것을 모으는 것은 매우 어렵고, task를 확장할 때마다 반복해야 한다.
- 큰 모델에서 좁은 분포의 데이터를 학습시키면, 잘못된 상관관계를 학습할 수 있다. pre-training 단계와 fine-tuning 단계를 사용한 모델들에서 이런 문제가 있는데, 이러한 모델들은 일반화가 잘 안 되는 문제가 있다.
- 인간은 새로운 lagnuage task를 배우기 위해, 많은 데이터를 필요로 하지 않는다는 점이다. 인간의 언어능력에는 일반화와 적용을 자주 활용하는데, NLP 모델도 이러한 인간의 언어 능력과 동일한 수준이 되어야 한다. (task-agnostic은 그렇지 않다는 뜻인 듯하다.)
- 이러한 문제를 풀기 위해, meta-learning을 활용한 방법들이 있다. 몇 가지 방법들이 등장했지만(특히, GPT-2), fine-tuning 방법에 비해 성능이 매우 떨어진다.
- 한편, Language modeling의 최근 트렌드는 model의 capacity를 키우는 것이다. 이러한 트렌드에서 model의 parameter를 키울수록 언어모델의 성능이 향상되는 경향이 있음을 볼 수 있다. (이전까지 17 billion paramter까지 등장)
[모델 소개]
- 이 논문에서는, 175 billion의 parameter를 사용하는 "GPT-3"이라는 language model을 실험하여, model의 parameter가 커질수록 성능이 향상됨을 확인한다.
- 또한, GPT-3을 각각 few-shot learning, one-shot learning, zero-shot learning을 통해 학습하고, 비교해 본다.
[실험 결과]
- Few-shot에서 단어에서 관계없는 symbol을 지우는 간단한 task를 수행해 보았을 때, task에 대한 설명이 많을수록(zero에서 few shot으로 갈수록), 성능이 향상되었고, model의 parameter가 많을수록 성능이 급격하게 향상되는 것을 보인다.
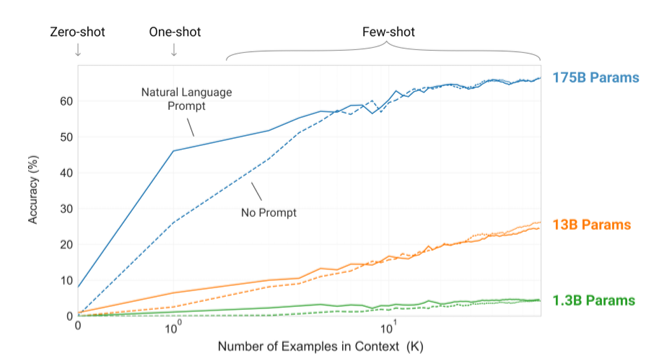
- GPT-3이 약한 분야도 있는데, inference task나 reading comprehension과 같은 분야이다.
GPT-3 Approach
- model, data, training을 포함한 pre-training 과정은 model의 크기, dataset의 다양성, 길이, 크기가 커졌다는 것을 빼고는 GPT-2의 방법과 비슷하다.
2023.05.27 - [NLP 논문] - GPT-2 (Language Models are Unsupervised Multitask Learners) 논문 리뷰
GPT-2 (Language Models are Unsupervised Multitask Learners) 논문 리뷰
GPT-2 배경 설명 GPT-2는 OpenAI에서 2019년 발표한 논문이다. GPT-2는 기존의 대규모 LM 구조인 GPT-1의 구조를 따르지만, 학습을 Unsupervised Multitask Learning을 사용하여, 범용성 있는 자연어처리를 할 수 있
devhwi.tistory.com
- in-context learning도 GPT-2 논문의 방법과 비슷하지만, context 내에서 구조적으로 조금 다른 몇 가지 setting을 시도해 볼 수 있다. task-specific 데이터를 얼마나 활용하냐에 따라, 4가지 setting으로 분류한다.
- Fine-Tuning (FT) : 최근에 가장 일반적인 방법이다. 원하는 task에 맞는 데이터셋을 통해 학습한다. 이 과정에서 수많은 데이터가 필요하다. FT의 장점은 성능이 매우 좋다는 점이다. 가장 큰 단점은 각 task를 학습할 때마다, 수많은 데이터가 필요하다는 점이다. GPT-3도 FT로 학습할 수 있지만, 논문의 목적은 성능이 아니기 때문에, 별도로 학습하지는 않았다.
- Few-Shot (FS) : inference 과정에서 conditioning으로 이용할 수 있는 약간의 task에 대한 설명이 주어지지만, 직접 학습에 활용하지는 않는다. FS는 task에 대한 설명과 함께 task에 대한 K개의 example들이 제공된다. (K를 model의 context window라고 하고, 대략 10~100의 값을 갖는다.) FS의 장점은 task-specific 한 데이터를 많이 줄일 수 있다는 것이고, narrow distribution에서 학습할 수 있는 잘못된 상관관계에 대한 가능성이 줄어든다는 것이다. 단점은 FT 방식의 SOTA에 비해 성능이 떨어진다는 점이다. 또한, task specific한 데이터가 여전히 필요하다는 점이 문제이다.
- One-Shot (1S) : task에 대한 example이 하나만 주어진다는 것이 Few-shot과 다른 점이다. 굳이 one-shot을 few-shot과 나누는 이유는 one-shot이 인간의 커뮤니케이션과 비슷하기 때문이다.
- Zero-Shot (0S) : 어떤 task인지에 대한 설명만 있고, 아무 example이 주어지지 않는다. 이 방법은 편의성과 확장성, 잘못된 상관관계를 피할 수 있는 점등에서 매우 좋지만, 학습이 매우 어렵다.

[Model]
- Sparse Transformer 논문의 sparse attention을 사용한 것 외에는 GPT-2와 같은 모델과 아키텍처를 사용하였다.
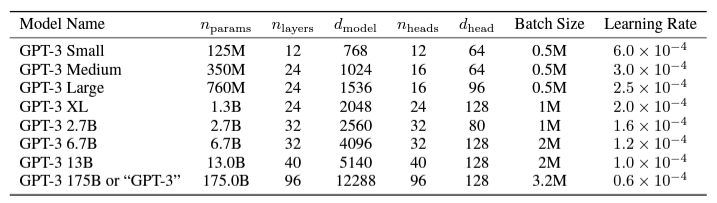
- model size와 성능 간의 상관관계 확인은 ㄹ위해, 8가지 다른 size의 모델을 사용했다. (125 millions ~ 175 billions)
- 이 중, 제일 큰 모델을 GPT-3이라고 한다.
[Training Dataset]
- 데이터가 풍부한 Common Crawl Dataset을 사용하였지만, 필터링되지 않은 데이터가 많이 섞여있어서, 데이터셋의 품질을 향상하기 위한 3가지 방법을 추가하였다.
- Common Crawl Dataset에서 high-quality reference corpora와 비슷한 데이터들을 다운로드하였다.
- 문서 수준에서 퍼지 일치 기반 중복 제거를 활용하여, overfitting 등을 방지하였다.
- 이미 알려진(앞선 NLP 논문등에서 활용), high-quality reference corpora 데이터들을 데이터셋에 포함하였다.
- 단순히 양에 따라서 가중치를 둔 것이 아닌, 데이터셋에 품질이 높을수록 높은 가중치를 두었다. (아래 weight in training mix에 해당)

[Training Process]
- large model일수록 큰 batch size를 사용하지만, 적은 learning rate를 필요로 한다.
- 학습과정에서 gradient noise scale을 측정하여, batch size 선택에 사용하였다.
- Out of memory를 막기 위해, model parallelism을 사용했다.
Results
- size가 각기 다른 8개의 GPT-3 모델의 learning curve를 비교하였는데, size가 큰 모델일수록 언어모델의 성능이 향상됨을 보인다.
- 이 과정에서, traigning compute와 performance는 power-law를 따른다고 알려졌는데, 모델 size가 일정 수준 이상에서는 power-law의 기댓값보다 더 좋은 성능을 보였다.
- 이것이 training dataset을 cross-entropy를 통해 학습해서(외워버려서) 그런 것 아닐까 하는 의심이 들 수도 있지, cross-entropy가 다양한 NLP 분야의 task에서 일관적으로 성능 향상을 보임을 보인다.

1. Language Modeling
- Penn Tree Bank(PTB) dataset에서 zero-shot perplexity를 계산하였다.
- training dataset에 포함된 Wikipedia와 관련된 4가지 task들은 제외했다.
- 새로운 SOTA가 되었다.

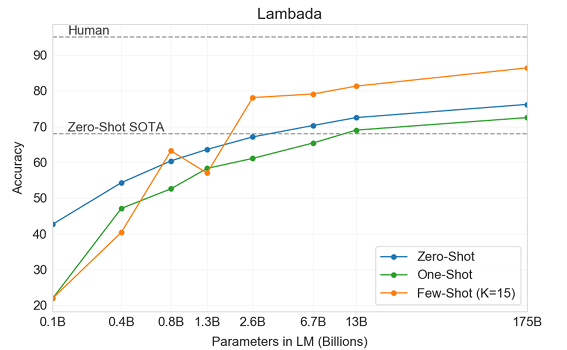
[LAMBADA]
- LAMBADA dataset은 text 내에서 long-range dependency를 테스트한다. (context를 읽고, sentence의 마지막 word를 추정하는 문제)
- Zero-Shot 환경에서 기존 SOTA보다 8%가량 좋은 성능을 보였다.
[HellaSwag]
- HellaSwag dataset은 story와 몇 가지 instruction이 주어지면, 가장 best의 ending을 뽑는 문제이다.
- StoryCloze dataset은 story에 따른 가장 그럴듯한 ending sentence를 뽑는 문제이다.
- 둘 다, SOTA보다는 떨어지지만, 좋은 성능을 얻었다.

2. Closed Book Question Answering
- Closed Book Question Answering은 다양한 지식에 대한 context가 없는 답변을 생성하는 Task이다.
- Model Size가 커졌을 때(GPT-3)에서 SOTA를 넘어서는 결과를 보여주었다. (아마도, task 자체가 광범위함을 포함하고 있어서, task-specific 학습이 크게 힘을 발휘 못하는 것 같다.)

3. Translation
- Translation의 학습에서는 93% 텍스트가 영어였고, 7% 만 다른 언어들을 포함하였고, 별도의 목적함수를 사용하지 않았다. (그냥 언어 구분 없이 똑같이 학습하였다.)
- Zero-Shot 환경에서는 기존 Zero-Shot들보다 오히려 성능이 낮지만, Few-Shot 환경에서는 특정 task에 한해서는 Supervised SOTA를 넘기도 하였다.

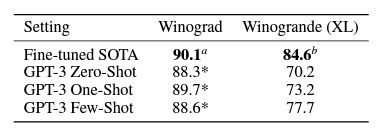
4. Winograd-Style Task
- 해당 Task는 대명사가 지칭하는 것을 맞추는 문제로, 추론 능력을 확인할 수 있다.
- SOTA에 비해서는 낮지만, RoBERTa에 근접할 정도로 좋은 성능을 보인다.

5. Common Sense Reasoning
- 특정 데이터셋에서는 SOTA를 보였지만, 다른 데이터셋에서는 낮은 성능을 보여주었다.
- 전체적으로 OpenBookQA를 제외한 데이터셋에서는 Task 설명이 큰 효과를 보지 못했다.

6. Reading Comprehesion
- GPT-3이 약한 분야이다. CoQA를 제외하고는 SOTA와 매우 큰 성능 차이가 난다.

7. Super GLUE
- BERT와의 비교를 위해 SuperGLUE를 Test 한다.
- SOTA에는 못 미치지만, 대부분의 task에서 BERT와 필적하거나, 오히려 더 높은 성능을 보여주기도 한다.


이외, 많은 Task들이 있지만, 대체적으로 비슷한 경향을 보여줘서, Result는 여기까지만 넣도록 하겠다.(힘들다.)
다만, 숫자 연산이나 뉴스 기사 생성, 문법 교정 등 다양한 분야에서 좋은 성능을 보여준다.
Memorization에 대한 검증
- GPT-3의 학습 데이터가 매우 방대하고, Web Crawling을 통해 만들어졌기 때문에, Training dataset에 원하는 Benchmark의 데이터가 포함되어 있을 가능성이 있다. (Data Contamination이라고 표현한다.) 즉, memorization으로 위의 좋은 performance를 낼 수 있다는 것이다.
- Training Curve를 보았을 때, 학습에 따라 Validation Loss와 Train Loss가 비슷한 추세로 줄어드는 것을 볼 수 있는데, 이것은 memorization이 없다는 증거가 된다. (특정 task를 외웠으면, train loss만 급격히 줄어드는 구간이 있을 것이기 때문에)

- 이것 말고도, memorization을 증명하기 위해, 데이터셋을 clean 하는 실험이 있는데, 실험 내용이 사실 이해가 잘 안 간다. 여하튼 Data를 Clean해도 성능에 딱히 영향이 없기 때문에, memorization은 아니라는 뜻이다.

Limitations
- GPT-3는 좋은 성능을 보여주었지만, 몇 가지 한계가 있다.
- 성능적 한계 : 몇가지 NLP task에 대해서는 좋지 않은 성능을 보여준다.
- 구조 & 알고리즘의 한계 : GPT-3은 bidirectional 구조나 denoising 같은 NLP 분야의 성능을 향상하는 방법들은 고려하지 않았다.
- 본질적 한계 : 본 논문은 LM을 scaling up 하는 것에 집중하였는데, pretraing objective에 근본적 한계가 있다. 현재 obejective는 모든 token을 동일한 가중치를 준다. 즉, 중요한 token을 예측하는 것이 NLP 성능 향상에 더 중요하지만, 모두 동일하게 학습한다. 단순 Scaling을 떠나서(한계가 있기 때문에), NLP의 목적을 위한 objective 등을 학습해야 할 것이다.
- pre-training 과정에서 비효율성 : GPT-3은 인간에 비해 너무 많은 텍스트를 학습한다. 학습과정에서 효율성을 향상해야 한다.
- Few-Shot learning의 불확실성 : 실제로 GPT-3이 Few-Shot Learning을 통해 학습한 것인지 모호하다.
- Expensive Cost : GPT-3의 parameter가 매우 많기 때문에 training & inference cost가 매우 크다.
- 설명 불가능 : 모든 Deep Learning이 겪는 문제처럼 GPT-3도 결과에 대한 해석이 불가능하다. Training data에 대한 bias가 발생할 수 있다.
Reference
Brown, Tom, et al. "Language models are few-shot learners." Advances in neural information processing systems 33 (2020): 1877-1901.
총평
- 논문이 매우 길고, 저자도 실험도 매우 많다. 그래서 그런지 읽기 매우 힘들었다. (내 착각인지 모르겠지만, GPT-2와 다르게 논문이 약간 문과틱 감성이 난다.)
- 실험이 매우 많고, 한계와 사회적 파급력 등에 대해서 매우 자세하고 광범위하게 다뤄서, 정말 좋은 논문이다.
- 다만, Parameter가 매우 크고, Task example이 정교하게 만들어진 것 같아, 재현을 하기는 어려울 것 같다.
'NLP 논문' 카테고리의 다른 글
| InstructGPT (Training language models to follow instructions with human feedback) 논문 리뷰 (1) | 2023.07.01 |
|---|---|
| PaLM(Scaling Language Modeling with Pathways) 논문 리뷰 (1) | 2023.06.29 |
| DeBERTa(Decoding-enhanced BERT with disentangled attention) 논문 리뷰 (1) | 2023.06.06 |
| DistilBERT(a distilled version of BERT) 논문 리뷰 (4) | 2023.06.04 |
| RoBERTa (A Robustly Optimized BERT Pretraining Approach) 논문 리뷰 (1) | 2023.06.03 |



