반응형
PaLM 배경 설명
- PaLM은 google에서 2022년에 발표한 LLM 관련 논문이다.
- GPT 이후의 NLP 분야의 거의 모든 논문이 그랬듯, Model Paramter를 더 크게 늘렸고, GPT-3의 흐름을 따라, task-specific 한 model이 아닌, 다양한 NLP 분야를 cover 하는 모델로 학습된다.
- 사실 GPT 등장 이후로 LLM 모델에서의 구조 변화는 크게 없다. Model parameter를 계속 늘리고, 이에따라 성능은 계속 좋아진다. 따라서, 기존 LLM과 달라진 부분에 집중하여 논문 리뷰를 시작한다.
Abstract
- Language Model은 few-shot 방식을 사용하여, task-specific 학습에 필요한 데이터의 양을 줄이면서, 좋은 성능을 보여줬다.
- few-shot에서 scaling의 효과를 확인하기 위해, 540 billions parameter로 구성된 Transformer 기반의 Pathways Language Model(PaLM)을 소개한다.
- 이 논문에서는 PaLM을 multiple TPU Pods 들을 효율적으로 학습할 수 있는 "Pathway" 방법을 이용하여 학습한다.
- 여러 language understanding과 generation 분야에서 SOTA를 달성하여, scaling의 장점을 보여준다.
- 특히, 몇가지 task들에서는 finetuned 방식의 SOTA를 능가하는 좋은 성능을 보여주고, BIC-bench에서 인간의 능력을 뛰어넘는다.
- BIC-bench에서 model의 scale에 따라 performance가 discontinuous 한 향상을 보여준다.
- 또한, PaLM은 multilingual task와 code 생성에서 좋은 성능을 보인다.
Introduction
- 최근(이 당시) 몇년동안, 언어 이해와 생성 분야에서 large language model을 pre-training과 fine-tuning 방식으로 학습하는 방식으로 큰 성능 향상을 이뤘다.
- 하지만, 이러한 모델들은 finetuning 과정에서 상당한 양의 task-specific 데이터를 필요로 하고, task에 맞는 학습을 위한 cost가 든다.
- GPT-3은 large autoregressive language model들로 few-shot을 진행하는 방식으로 학습하여, 많은 양의 task-specific 데이터와 model parameter updating 과정이 필요 없도록 하였다. (GPT-3 관련 내용은 아래 링크 참조)
2023.06.12 - [NLP 논문] - GPT-3 (Language Models are Few-Shot Learners) 논문 리뷰
GPT-3 (Language Models are Few-Shot Learners) 논문 리뷰
GPT-3 배경 설명 GPT-3은 요즘 많이 사용하는 ChatGPT의 근간이 된 논문으로, 2020년 OpenAI에서 NIPS에 발표한 논문이다. Language Model의 parameter가 꾸준히 늘어가는 추세였는데, GPT-3에서는 기존의 가장 큰
devhwi.tistory.com
- 그 후로, GPT-3 기반의 후속 모델(GLam, Gopher, Chinchilla, LaMDA 등)들이 등장해 좋은 성능을 보였다.
- 이러한 모델들의 성능 향상을 위한 주요 접근 방법은 다음과 같다.
- model의 depth와 width를 늘린다. (model size를 늘림)
- model의 학습을 위한 token의 양을 증가
- 다양한 dataset을 사용하거나, dataset을 정제
- sparsely activated module등으로 학습 cost는 유지하면서 model capacity를 증가
- 이 논문에서도 위의 방식들을 따라, 780 billion token을 이용하여 540 billion parameter를 가진 Transformer 기반 model을 학습한다.
- 이를 위해, "Pathways"라는 수천개의 acclerator chip들 사이에 large network 학습을 효율적으로 해주는 방식을 도입한다.
- 이 논문에서 소개한 모델 PaLM은 natural language , code, mathematical reasoning 등의 task들에서 few-shot 방식의 SOTA를 달성했다.
Model Architecture
- PaLM은 몇가지 변경을 제외하고. Transformer의 decoder-only 모델을 그대로 따른다.
- 기존 Transformer 모델들과 달라진 점은 다음과 같다.
- SwiGLU Activation : SwiGLU는 Relu를 대체하기 위해, 구글이 개발한 Swish Activation 함수에 GLU(Gated Linea Unit)을 적용한 함수이다. 사용한 이유는 기존 연구들에서 성능이 좋아서라고 한다.
- Parallel Layers : 병렬 처리를 해, 기존의 Transformer block의 식을 바꿨다. Large Scale에서 15% 정도 학습 속도가 빠르지만, 성능 하락은 모델이 커질수록 거의 없다고 한다.
- 기존 $$ y = x+ MLP(LayerNorm(x+Attention(LayerNorm(x)))) $$
- 변경 $$ y = x+ MLP(LayerNorm(x))+Attention(LayerNorm(x)) $$
- Multi-Query Attention : query, key, value의 feature size가 [k, h]인 기존 transformer 구조와 달리, key와 value를 [1, h] 크기로 사용한다. (query는 [k, h]) 이것이 model 성능에 영향을 미치지 않으면서, 학습 시간 cost 절감에 큰 역할을 한다.
- RoPE Embedding : position embedding에 long-sequence 처리에 유리한 RoPE Embedding을 사용하였다.
- Shared Input-Output Embeddings
- No Biases : Bias를 사용하지 않았다. 이것이 large model 안정성을 높여준다고 한다.
- Vocabulary : SentencePiece(256k token)을 사용했다.
Model Scale Hyperparameters
- 3개의 모델(8B, 62B, 540B)을 사용했다.

Training Dataset
- PaLM의 pretraining dataset으로는 high-quality의 780 billion의 token이 사용되었다.
- dataset은 webpage, books, Wikipedia, news articles, source code, social media conversation등 다양한 소스에서 가져왔다.
- 특히, Github에서 Source code를 가져왔는데, Java, HTML, JavaScript, Python, PHP, C# 등등의 196GB의 소스 코드를 포함한다. 또한, Source code 수집 시, 중복을 제거하여 다양한 코드 등을 수집했다.

Training Infrastructure
사실 PaLM이 주목받는 이유가 Pathways를 사용하는 해당 Chapter 때문인것 같다. 아마도, Pathways를 논문으로 굳이 읽는 이유는 점점 늘어나는 LLM의 학습을 위해 엔지니어링의 최강자인 Google은 어떤 방법을 사용했을까? 때문일 것이다.
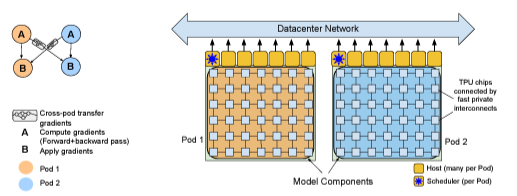
- 우선, PaLM의 codebase는 JAX와 T5X이고 TPU v4 Pods를 통해 학습되었다. PaLM 540B는 data center network(DCN)로 연결된 2개의 TPU v4 Pods를 통해 model parallelism과 data parallelism을 사용해서 학습되었다.
- 각 TPU Pods들은 3072개의 TPU v4 chip들로 구성되어 있고, 768 hosts에 연결되어 있다. (즉, 총 6148개의 chip과 1536개의 host가 존재한다.)
- 이 논문에서는 pipeline parallelism(layer 등의 단위의 parallelism을 사용)을 사용하지 않은 것을 큰 장점으로 여기는데, pipeline parallelism에는 몇 가지 문제가 있기 때문이다.
- pipeline 구조에서는 pipeline이 비어서 쉬게되는 devices들이 생긴다.
- 각 micro-batch의 weight를 불러오기 위해, 높은 memory bandwidth를 요구한다.
- 일부 케이스에서는 software complexity가 늘기도 한다.
- 이 논문에서는 pipeline 없이 PaLM 540B를 6144개의 TPU chip을 사용하여 학습했다는 것을 강조한다.
- 각 TPU v4 Pod은 model parameter들을 full copy 한다. (3072개 chip에 12개 방법의 model parallelism과 256개의 data parallism을 사용한다. 2가지 parallelism을 동시에 사용하는 것을 2D parallelism이라고 한다.)
[학습 방법]
- forward pass에서는 data parallel axis로 weight를 모으고, 각 layer로부터 하나의 fully sharded activation이 저장된다.
- backward pass 때, forward pass에 사용되었던, activation을 재사용하는 것이 아니라, activation을 다시 계산해서, 재생성하여 사용한다. 이것은 더 큰 배치에서 학습 처리량을 높이도록 해준다.
[Pathways]
- PaLM은 이름대로, TPU v4 Pod들에 Pathways system을 사용한다. PaLM은 Pathways의 client-server 구조를 사용하여 pod level에서의 2가지 방법의 data parallelism을 구현한다.
- Python client가 training batch의 절반씩을 각 pod으로 보내고, 각 pod은 forward와 backward computation을 data, model parallelism을 이용해 계산한다.
- Pod들은 gadient를 다른 pod에 보내고, 각 pod은 local(자신이 만든 것)과 remtoe(다른 pod으로부터 받은 것) gradient를 모아서, parameter update에 사용한다.
- 이런 구조는 single Pod을 이용한 학습보다 정확히 2배의 throughput 증가는 일어나지 않고, 약 1.95배 정도의 throughput 증가를 이끄는데, 이것은 network적 이슈와 관련있다. 따라서, network 설계를 열심히 했다고 한다.
Training Efficiency
- 이전의 많은 language model에서는 accelerator efficiency를 hadware FLOPs utilization(HFU)를 통해 진행하였다. 이것은 이론적 peak FLOP 개수로 관찰되는 FLOP 개수를 나눈 것이다.
- 하지만, 이 지표는 약간의 문제가 있다.
- hardware FLOP의 갯수는 system-depedent와 implementation-dependent, compiler의 design chice에 따라 달라진다.
- 관찰되는 FLOP 갯수는 count와 track에 사용되는 방법론에 따라 달라진다. 이것은 hardware performance를 통해 측정되는 것이 아닌, analytical accounting을 사용하기 때문이다.
- 이러한 문제가 있어서, LLM training efficiency를 측정하기에 HFU는 충분치 않다.
- 이 논문에서는 implementation indepenet 하고 system efficiency에 따라 정확한 비교를 가능하게 해주는 model FLOPs Utilization(MFU)를 제시한다.
- MFU는 observed throughput(tokens-per-seconds)를 이론상 최대 system operating peak FLOP으로 나눈 값이다.
- 특히, 이론상 최대 throughput은 forward와 backward pass를 계산하면 된다.
- 여하튼, 본인들이 만든 지표로 비교해보았을때, PaLM이 가장 효율적인 연산을 하고 있다고 한다.

Evaluation
- 역시, parameter를 많이 사용해서, 기존 few-shot 기반의 SOTA들을 모두 갱신하였다.

- 심지어 SuperGLUE등에서는 fine-tuning 기법들과 맞먹을 정도로 좋은 성능을 보여준다.

- Reasoning : GSM8K에서 8-shot evaluation을 진행했을 때, 기존 SOTA인 GPT-3을 이긴다.

- Few-shot의 장점인 다양한 분야에 적용성에서, 놀랄만한 부분은 Code를 고치는 것이나 Translation에서도 좋은 성능을 보인다는 것이다.
Conclusion
- 이 논문에서는 few-shot LM 방향으로의 연장선인 540B parameter로 구성된 PaLM을 소개한다.
- PaLM은 NLP 29개 분야 중 28개에서 few-shot SOTA를 기록했다. 또한, BIG-bench에서 5-shot LaLM은 인간의 평균 performance보다 높은 성능을 보였다. source code 이해나 생성에서도 좋은 성능을 보였다.
- reasoning에서 chain-of-though prompting을 사용했을 때, 좋은 모습을 보였다.
- 이에 따른 결론은 다음과 같다.
- few-shot NLP에서 scale에 따른 성능 향상은 아직 끝나지 않았다. (log-linear하게 증가했다.) 이 성능 향상은 사실은 discontinuous 하다.
- reasoning task들에서 보인 성과들은 중요한 의미를 갖는다. 이것은 model의 결정 과정에서 어떤 과정을 이용하여 최종 결과가 나왔는지를 end user에게 설명할 수 있게 할 것이다. 아직 멀었지만, 잘 만든 prompt가 이것을 가속화할 것이라고 한다.
- network architecture와 training schema에 많은 여지를 남겼다. Pathways를 시작으로 많은 구조들이 생겨날 수 있을 것이다.
Reference
Chowdhery, Aakanksha, et al. "Palm: Scaling language modeling with pathways." arXiv preprint arXiv:2204.02311 (2022).
총평
- 읽은 논문 중, 비교적 최근 논문인데, 이쯤때부터, 모델 크기가 커질수록 성능은 무조건 커진다는 가정하에, 어떻게 빠르고 효율적으로 학습할 것인가 하는 문제에 봉착한 것 같다.
- 적어도 NLP 분야에서는 앞으로 엔지니어와 H/W의 비중이 점점 더 커질 것 같다.
'NLP 논문' 카테고리의 다른 글
| LLaVA: Vision Instruction Turing 논문 리뷰 (41) | 2023.10.15 |
|---|---|
| InstructGPT (Training language models to follow instructions with human feedback) 논문 리뷰 (1) | 2023.07.01 |
| GPT-3 (Language Models are Few-Shot Learners) 논문 리뷰 (5) | 2023.06.12 |
| DeBERTa(Decoding-enhanced BERT with disentangled attention) 논문 리뷰 (1) | 2023.06.06 |
| DistilBERT(a distilled version of BERT) 논문 리뷰 (4) | 2023.06.04 |



