LLaVa배경 설명
- LLaVa는 2023년 NeurIPS 발표된 논문으로, multimodal LLM에 대해 다룬 논문이다.
- multimodal LLM에 대한 부분도 놀랍지만, 코드와 weight를 open source로 발표하여, 많은 관심을 받고 있다.
- https://llava-vl.github.io/
LLaVA
Based on the COCO dataset, we interact with language-only GPT-4, and collect 158K unique language-image instruction-following samples in total, including 58K in conversations, 23K in detailed description, and 77k in complex reasoning, respectively. Please
llava-vl.github.io
Abstract
- 최근 LLM을 이용해 instruction-following data를 생성하여 instruction 능력을 향상하는 연구들이 많이 이뤄지고 있다. 하지만, multimodal 분야에서는 아직 많이 연구되지 않았다.
- 이 논문에서는 언어만을 사용하는 GPT-4를 이용하여 multimodal language-image instruction-following 데이터를 만든다.
- 이를 이용한 instruction tuning을 통해, 이 논문에서는 LLaVa(Large Language and Vision Assistant)라는 vision encoder와 LLM을 연결한 end-to-end model을 소개한다.
- 초기 실험에서 LLaVa는 multimodal chat 능력에서 multimodal GPT-4에 대한 85.1%의 상대적 score를 보였다.
- Science-QA로 finetuning 하였을 때, LLaVA와 GPT-4의 시너지는 새로운 SOTA인 92.53%의 정확도를 보였다.
Introduction
- 인간은 vision과 language 등 다양한 채널을 통해 세상을 인지한다.
- LLM은 최근 다양한 분야에서 좋은 성능을 내고 있지만, text만을 다룬다.
- 이 논문에서는 "visual instruction-tuning"을 소개한다. 먼저, instruction-tuning을 multimodal space로 확장하여, vision 분야의 general-purpose를 위한 초석을 쌓는다.
- 논문의 Contribution은 다음과 같다.
- Multimodal instruction-following data : 가장 큰 제약은 vision-language instruction-following data가 적다는 것이다. 논문에서는 data 생성 방법을 소개하고, ChatGPT나 GPT-4를 통해 image-text pair들을 적절한 instruction-following format으로 변환하는 파이프라인을 소개한다.
- Large multimodal models : open-set visual encoder인 CLIP과 LLaMA를 연결하고, 앞서 만든 데이터를 통해, 이 둘을 end-to-end로 학습한다. 특히, GPT-4로 진행했을 때, Science QA multimodal reasoning dataset에 대해 SOTA 성능을 보였다.
- Open_Source : Code와 model checkpoint 등을 모두 공개하였다.
GPT를 이용한 Visual Instruction Data 생성
multimodal instruction following 데이터는 부족한데, 최근 GPT model의 text-annotation task에서 성공에서 영감을 받아, ChatGPT/GPT-4를 이용한 multimodal instruction-following 데이터를 생성하는 방법을 제시한다.
- Image와 그에 대한 Caption이 있는 데이터가 있을 때, 가장 간단한 방법은 GPT-4를 통해 Caption을 해석하고, 그에 대한 Question들을 가지고 질문하는 것이다.
→ 쉽게 생각하면, 아래와 같이 이미지 묘사를 넣고 퀴즈를 내는 것이다.
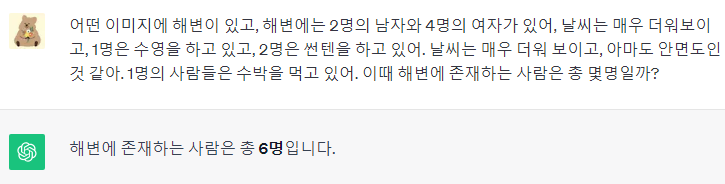
- 하지만, 이렇게 하면 만들어지는 데이터의 다양성이 떨어지고, 깊이 있는 추론을 포함하는 instruction과 response를 만들지 못한다. 이 현상을 완화하기 위해, GPT에 이미지를 묘사할 수 있는 2개 type의 데이터를 제공한 뒤 질문을 진행한다.
1. Image를 묘사하는 Caption 데이터
2. 이미지 내, 물체들에 대한 Bounding Box 데이터(각 box에는 해당 물체의 종류와 위치 정보를 담고 있다. 즉, GPT가 이미지를 input으로 사용하지는 못하지만, text 형태로 이미지 내 물체들의 위치 정보와 종류를 인식할 수 있는 것이다.)

- COCO image를 이용하여 3개 타입의 instruction-following dataㄹ르 생성하였다. 데이터 생성 시에는 인간이 만든 prompt를 이용하여, 데이터를 얻었다. (총 158K)
- Coversation : 인간과 GPT간 이미지에 대한 Q&A 대화를 생성했다. GPT가 이미지를 보고 있는 것처럼 질문을 했다. 질문에는 물체 종류, 물체 개수, 물체의 행동, 물체의 위치, 물체 사이의 상대적 위치 등이 포함된다. (58K)
- Detailed Description : Image에 대한 자세한 설명을 요청하는 질문들을 만들어 요청하였다.(23K)
- Complex Reasoning : 앞선 2개의 데이터들은 이미지 자체에 집중하지만, GPT에 깊은 추론을 요하는 질문들을 진행했다. (77K)

- 초기에는 ChatGPT와 GPT-4를 모두 활용했으나, GPT-4의 quality가 더 좋아서 GPT-4만 사용했다.
Visual Instruction Tuning
[구조]
- Model의 주된 구조적 목표는 visual model과 pre-trained LLM을 효과적으로 결합하는 것이다.
- LLM으로는 LLaMA를 사용하였다.
- 우선 이미지(Xv)를 CLIP visual encoder에 넣어서, Feature(Zv)를 뽑고, training 가능한 Linear Layer를 거쳐, Language model의 embedding space와 동일한 dimension의 language embedding token(Hv)를 만든다.
- 논문에서는 가볍고 간단한 구조를 생각해서 Linear layer를 사용했다고 하는데, 다른 여러 방식을 사용한 embedding은 future work로 남기겠다고 한다.

[학습]
- 각 이미지마다 T개의 turn이 있는 conversation data를 생성하였고(첫 번째 Question, 첫 번째 Answer, 두 번째 Question,... 이런 형식으로), 이들을 sequence형태로 연결하였다.
- 이때, 첫번째 turn의 경우에는 이미지 Feature를 (1) 질문 앞에 두는 경우, (2) 질문 뒤에 두는 경우를 random 하게 결정한다.


- 학습을 위해서는 기존 LLM의 방식처럼 이전 token들을 통해, 현재 token을 추정하는 방식의 학습을 진행한다. 따라서, 학습을 위한 Loss도 기존 LLM과 비슷하다. 수식에 보면, 현재 token 추정 시, 단순 과거 Q&A 데이터뿐만 아니라 이미지 Feature도 함께 사용한다는 것이 기존 LLLM과의 차이이다.

- LLaVa model 학습에는 2가지 stage가 존재한다.
1. Pre-training for Feature Alignment
- LLaVa의 구조에서 이미지를 word embedding으로 변환할 때, Linear Layer를 사용하는데, 해당 논문의 관심사가 multi-modal Language Model인 만큼, 이미지를 얼마나 잘 word embedding으로 변환하냐가 매우 중요하다.
- 이를 위해, CC3M 이미지-텍스트 데이터를 single turn conversation 형식으로 만들어, LLM과 visual encoder의 파라미터를 freeze 한 뒤, Linear layer만 학습을 진행했다.
- 아마, visual encoder와 LLM은 pre-trained model을 사용했지만, Linear layer는 별도의 학습된 weight를 사용한 게 아니어서 해당 stage가 있는 것으로 생각된다.
2. Fine-tuning End-to-End
- visual encoder는 계속 freeze 시켜놓고, LLM과 Linear layer를 같이 학습한다.
- 학습에는 앞서 위에서 언급했던 3개 type의 데이터 (Conversation, Detailed Description, Complex Reasoning)와 저자들이 추가적으로 고안한 ScienceQA 데이터를 이용하였다. ScienceQA 데이터는 과학적 질문에 대한 multimodal 데이터 셋이다. ScienceQA는 single turn conversation 형식으로 사용했다.
Experiments
[multi modal chatbot]
- LLaVa의 이미지 이해력과 conversation 능력을 보기 위해, Chatbot 데모를 고안했다. 우선, GPT-4 논문에 있는 Example들을 사용했다.
- 비교를 위해, prompt와 response는 multimodal GPT-4 논문에 존재하는 것을 사용하였고, 다른 모델과 결과도 해당 논문에서 인용했다. (multimodal GPT-4, BLIP-2, OpenFlamingo)
- 놀랍게도, LLaVA는 매우 적은 양의 multimodal 데이터로 학습했음에도 불구하고, 2개의 example에서 multimodal GPT-4와 거의 비슷한 수준의 reasoning 결과를 보임을 확인했다. 이때, 2개의 example들은 LLaVA의 학습에 사용된 이미지의 범위가 아님에도 (학습 시, 데이터를 외운 것이 아니다.) 장면을 이해하고, question에 대한 적절한 대답을 했다.

- 단순 example 비교 뿐 아니라, LLaVA의 성능을 측정하기 위해, GPT-4를 이용하여, ouput의 quality를 측정했다.
- 구체적으로 COCO validation에서 30개의 이미지를 무작위로 추출하여, 앞서 언급한 3개 종류의 question을 만들고, LLaVA가 이미지와 해당 question을 기반으로 answer를 내도록 했다. 그리고, question, ground-truth bounding box, captions을 이용하여 GPT-4에게 answer을 내도록 하여, reference를 생성했다. (즉, GPT-4 대비, LLaVA의 성능을 측정하겠다는 뜻)
- 그러고 나서, GPT-4를 이용하여 helpfulness, relevance, accuracy, detail 정도의 quality를 1~10까지 점수로 나타내게 했다. (점수가 높을수록 좋은 것)
- 가장 좋은 모델은 GPT-4의 85.1% 수준의 매우 좋은 성능을 보였다.


Reference
Liu, H., Li, C., Wu, Q., & Lee, Y. J. (2023). Visual instruction tuning. arXiv preprint arXiv:2304.08485.
총평
- Open source로 모든 것을 공개했다는 점이 우선 제일 놀라웠다.
- GPT-4를 이용해서 데이터를 만드는 방식에서 bounding box를 텍스트 형식으로 제공하는 부분에서 어떻게 이런 생각을 할 수 있지라는 생각이 들었다.
- multimodal LLM을 Q&A에 적용하였는데, Open source로 소스가 제공된 만큼 objective function이라던지, 데이터의 방식에서 금방 새로운 아이디어가 적용되어, 더 다양한 부분에 사용될 수 있지 않을까 싶다.
- 이미 있는지는 모르겠지만, 소리 등등의 다른 modal에도 적용할 수 있을 것 같다.
'NLP 논문' 카테고리의 다른 글
| LoRA: Low-Rank Adaptation of Large Language Models 논문 리뷰 (27) | 2024.07.30 |
|---|---|
| BitNet: Scaling 1-bit Transformers for Large Language Models 논문 리뷰 (24) | 2024.03.26 |
| InstructGPT (Training language models to follow instructions with human feedback) 논문 리뷰 (1) | 2023.07.01 |
| PaLM(Scaling Language Modeling with Pathways) 논문 리뷰 (1) | 2023.06.29 |
| GPT-3 (Language Models are Few-Shot Learners) 논문 리뷰 (5) | 2023.06.12 |



