반응형
2025.12.16 - [Data Science] - 벡터 DB 기본 개념 : ANN 인덱스 (3)
벡터 DB 기본 개념 : ANN 인덱스 (3)
2025.12.09 - [Data Science] - 벡터 DB 검색 기본 개념 : Embedding (2) 벡터 DB 검색 기본 개념 : Embedding (2)2025.12.08 - [Data Science] - 벡터 DB 검색 기본 개념 : Embedding, ANN 개요 (1)지난 글에서는 벡터 DB가 무엇이고
devhwi.tistory.com
지난 글에서 벡터 DB 내 검색에 대한 내용을 정리했다. ANN 인덱스를 이용하여 벡터 DB의 검색을 빠르게 진행할 수 있지만, 실무에서는 벡터 DB만을 단독으로 사용하지 않고, 명시적 조건 (키워드, 메타데이터)과 함께 섞어 쓰는 경우가 많다. 이번 글에서는 벡터 DB가 가지는 한계점과 Hybrid Search가 필요한 이유를 알아본다.
벡터 DB의 한계
- 벡터 DB는 비정형 데이터를 맥락, 의미 기반으로 검색할 수 있게하여 기존 키워드 방식등의 한계를 극복하였다.
- 하지만, 벡터 DB만으로 검색하는 경우는 실무에서 많지 않다. 이것은 벡터 DB가 가지는 한계가 다음과 같기 때문이다.
1. 정확한 것을 찾는 데 약함
- 벡터 검색은 비슷한 것(특히, 유사어)을 찾는데 강하지만, 정확히 일치해야 하는 것을 찾는 데는 취약하다.
- 특히, 텍스트 기준 도메인 용어나 숫자, 고유명사, 제품명, 이미지 기준 정확한 카테고리 구분, 모양이 비슷하지 않지만 같은 대상 등을 찾는데 약하다.
- 예를 들어, 벡터 DB 검색에서는 "김민수"와 관련된 키워드를 검색하는 경우, "김민순", "김민숙"과 같이 유사한 단어들이 검색되는데, 단어 기준으로는 매우 유사하지만 실제 검색 의도와 다른 결과를 초래한다.
- 특히, RAG 파이프라인에 벡터 DB 검색을 넣는 경우에는 인간이 잘못된 검색 결과를 확인할 수 없기에 잘못된 LLM 응답으로 연결될 가능성이 높아진다.
- 따라서, 도메인 용어가 많은 RAG 환경에서는 BM25와 벡터 DB를 함께 활용하는 Hybrid Search나 BM25를 활용한 키워드 검색만을 단독으로 활용하기도 한다.
2. 검색 결과에 대한 통제와 설명이 어려움
- 벡터 DB의 검색 결과 순위는 점수의 해석이 직관적이지 않다. 이는 벡터 DB의 embedding 과정에 딥러닝 모델이 주로 사용되기 때문이다.
- 벡터 DB에서는 검색 결과 순위가 왜 그렇게 형성되었는지를 설명하기 매우 어렵다. 특히, embedding 모델이 어떤 데이터를 통해 어떻게 학습되었는지 정확히 알 수 없기에 더 어렵다.
- 벡터 DB에서 특정 조건을 반드시 포함시키는 제어가 까다롭다. 예를들어, 이미지 검색 시, "빨간색을 무조건 포함해야 한다."와 같은 조건을 구현하기 매우 어렵다. 텍스트 embedding 모델의 경우에도 프롬프팅을 통해 어느 정도 완화가 가능하지만, 완전한 조건을 걸기 매우 어렵다.
- 벡터 DB는 운영 중 튜닝 포인트가 명확하지 않다. 특정 이미지나 텍스트가 들어간 검색에서 약점을 보인 다고 해도, 그 부분만 해결하기 매우 어렵다.
3. 조건이 하나로 부족
- 실제 실무에서는 여러 모달을 모두 활용한 검색이나, 특정 범위 또는 조건 내에서 벡터 검색을 하는 경우가 많다.
- 예를 들어, 텍스트를 포함한 이미지 검색 때, 단순 이미지 벡터 내에서 유사 이미지 검색뿐 아니라, OCR을 활용한 키워드 검색을 섞어야 원하는 데이터를 검색할 수 있는 경우가 존재한다.
- 또한, 업로드 시점, 카테고리, 태그, 파일명 등등의 조건이 명시적으로 필요한 경우가 있는데, 이때마다 벡터 DB를 재구성하기는 어렵다.
Hybrid Search
- 위의 문제를 해결하기 위해 의미 기반 검색은 벡터 DB를 활용, 명시적 조건은 명시적 방식으로 처리하고, 이 결과를 하나의 Ranking으로 결합하는 Hybrid Search를 주로 활용한다.
- 하지만, Hybrid Search는 설계가 쉽지 않은데, 여러 검색 기준을 어떤 단계에서 어떻게 결합하느냐에 따라 검색의 품질이 매우 다르기 때문이다.
- 가장 대표적인 예가 BM25를 활용한 키워드 검색과 embedding을 활용한 RAG 검색을 결합하는 것인데, 두 검색의 결과의 의미와 스케일이 다르기 때문에 이 둘을 합쳐서 하나의 기준으로 만드는 데는 매우 많은 방법이 존재한다.
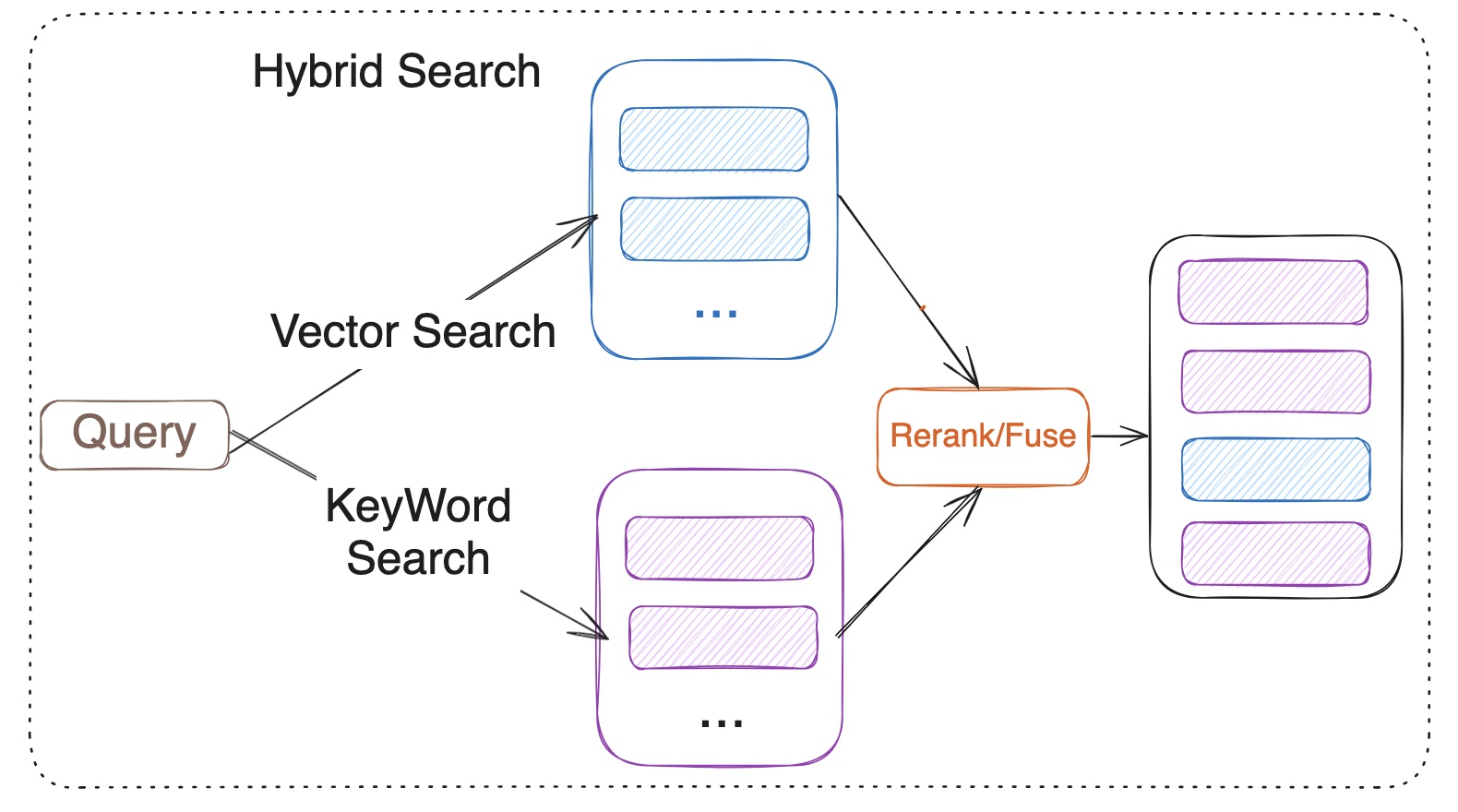
Hybrid Search에서의 신호들
- 검색의 결과를 제공하는 것을 신호라고 하고 이는 크게 3가지로 분류할 수 있다.
- 명시적 신호: BM25, TF-IDF, OCR 텍스트, 규칙 기반 필터 → 정확도가 높다. 설명 가능하다. 조건 제어가 가능하다.
- 의미 신호 : embedding 유사도, 이미지 embedding, 멀티모달 embedding → recall 확장에 강하다. 표현이 달라도 의미가 비슷한 데이터들을 잘 찾는다. 점수 해석이 어렵다.
- 메타데이터 : 날짜, 문서 타입, 권한, 중요도 가중치 → 검색 품질보다 필요 데이터를 판단하는 역할을 수행, ranking을 안정화하는 역할
Hybrid Search의 결합 전략
- 여러 신호는 스케일과 그 의미가 다르기 때문에, 이를 결합하기 위해서 결합 전략이 필요하다.
- 결합 전략은 어느 비즈니스로직 내에서 어느 검색을 할 것이냐에 따라 다르게 구성할 수 있어, 상황에 맞는 결합 전략을 택해야 한다.
1. 점수 결합
- 가장 단순하고 많이 쓰이는 방식이다.
- 여러 신호들을 점수로 나타내고, 이를 정규화하여 표현해야 한다.
- 각 신호의 값을 가중치를 곱해서, 더하여준다. 이때 3개의 신호의 스케일과 분산이 다르기 때문에 경험적으로 가중치 튜닝과 각 score에 대한 정규화가 필요하다.
- Final Score = α · (명시적 신호 score) + β · (의미 신호 score) + γ · (메타데이터 score)
- 점수 결합 방식은 구조가 단순해서 구현과 운영이 쉽다.
- 하지만, 서로 다른 신호 간 의미적 우선순위를 반영하기 어렵다는 점, 데이터셋 변화에 따라 가중치 변경이 계속 필요하다는 점이 단점이다.
2. Candidate Pool + Reranking
- 1차로 각각 검색을 통해 후보군을 넉넉하게 잡아놓고(빠르고, 많게), 2차로 reranking을 위한 구조(느리지만, 정교)를 따로 두어, 최종 정렬을 진행하는 구조이다.
- 이 구조를 통해서는 키워드 검색 같은 정확성이 요구되는 검색 결과와 맥락 정보가 필요한 벡터 검색의 결과를 모두 활용할 수 있어 최근에 가장 많이 활용된다.
- 하지만, reranker의 검색 품질, 속도에 따라 최종 검색 결과가 결정되기 때문에 좋은 reranker로 얼마나 빠르게 결과를 낼 것인가가 중요하다.
- 일반적으로 텍스트에서는 cross-encoder 기반의 reranker를 사용하거나 토큰 비용에 문제가 없다면 LLM에 그 적합도를 묻는 방식을 사용하기도 한다. 이미지에서는 CLIP 계열 reranker 모델이나 별도의 학습된 모델로 reranking을 진행한다. (Appearance로 후보군만 좁히고 → 해당 Class가 포함된 image classification model 활용)
- 후보를 모으는 방식도 단순히 합집합으로 모으는 것이 아니라, 신호 간 순서를 두어 순차적으로 지워가는 방식으로도 구현 가능하다.
- 최근에는 reranker가 RAG의 성능을 결정한다고 할 정도로 필수적인 방법으로 자리 잡았다.
Query
│
├─ BM25 Search → Top-K1
│
├─ Vector Search → Top-K2
│
└─ Metadata Filter
│
▼
Candidate Pool (Union)
│
▼
Reranker
│
▼
Final Ranking3. 조건 분기
- 모든 쿼리에 Hybrid Search를 적용하지 않고, 쿼리 성격에 따라 검색 전략을 분기하는 방식이다.
- 짧고 명확한 키워드는 BM25로 자연어 질문은 벡터 검색 중심 등으로 분기를 쳐, 더 적합한 검색이 되도록 한다.
- 실제 운영에서는 가벼운 LLM 모델을 앞에 두어 이를 판단하게 하기도 한다. 특히 랭그래프의 Router와 결합시켜 활용하면 구현도 매우 쉽다.
- UI 단에서 사용자가 쿼리 입력 단에 더 맞는 검색 조건을 선택하도록 하는 방법으로 더 명확하게 조건을 분기할 수도 있다.
- 불필요한 벡터 검색을 줄여 비용이 절감할 수 있고, 시스템 전체의 안정성이 높아진다.
Query ↓ Query Analyzer (Length / Intent / Type) ↓ ┌───────────────────────────────┐ │ Query Routing Decision │ └───────────────────────────────┘ │ │ │ │ │ │ ▼ ▼ ▼ BM25 Only Vector Only Hybrid Search (Keywords) (Natural Q) (Ambiguous) │ │ │ │ │ ┌──────────────┐ │ │ │ BM25 Search │ │ │ └──────────────┘ │ │ │ │ │ ┌──────────────┐ │ │ │ Vector Search│ │ │ └──────────────┘ │ │ │ │ │ Candidate Pool │ │ │ └──────────────┴───────→ Reranker │ Final Ranking
'Data Science' 카테고리의 다른 글
| 벡터 DB 기본 개념 : ANN 인덱스 (3) (3) | 2025.12.16 |
|---|---|
| 벡터 DB 검색 기본 개념 : Embedding (2) (1) | 2025.12.09 |
| 벡터 DB 검색 기본 개념 : Embedding, ANN 개요 (1) (1) | 2025.12.08 |
| DTW(Dynamic Time Warping) (1) | 2023.06.02 |
| PCA(Principal Component Analysis) (1) | 2023.05.04 |



