반응형
Prefix-Tuning 배경 설명
- Prefix-Tuning은 NLP 모델의 fine-tuning 과정의 비효율을 해결하기 위해 발표된 방법론으로 2021년 ACL에서 발표되었다.
- Pretrained model 전체를 fine-tuning하지 말고, prompting에 착안한 소규모의 parameter 학습만으로 fine-tuning과 비견하는 좋은 성능을 보인다.
Abstract
- Fine-tuning은 대규모 데이터에서 학습한 pre-trained model을 down-stream task에서 활용할 수 있게 하여 좋은 성능을 낸다.
- 하지만, model의 모든 parameter를 바꾸기 때문에, 각 task마다 전체 parameter를 저장해놔야 한다.
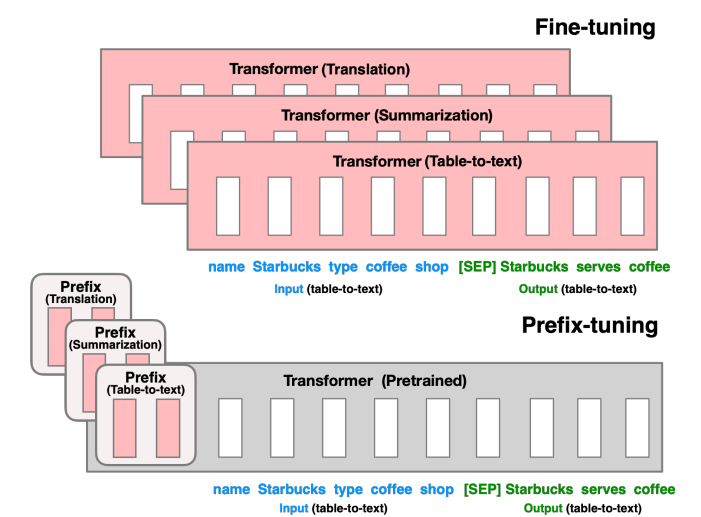
- 이 논문에서는 prefix-tuning이라는 자연어 생성 task에서 fine-tuning 없이, model의 parameter를 고정하고도 적은 양의 prefix (continuous task-specific vector)만을 optimize 하여 사용할 수 있는 방법을 제시한다.
- Prefix-tuning에서는 prefix를 virtual token으로 대하여 prompting처럼 활용한다.
- 성능 실험을 위해, GPT-2에서 자연어 생성, BART에서 요약 작업을 테스트해 보았는데, 전체 parameter의 0.1% 만을 학습해도 fine-tuning과 비슷하거나, 일부 상황에서는 더 좋은 성능을 보인다.
Introduction
[Fine-Tuning 방법]
- 대규모 pretrained model을 활용하여 원하는 각 task에 맞게 fine-tuning 하는 방법이 주류로 자리 잡았다.
- 하지만, fine-tuning 방법은 각 task마다, 전체 model의 parameter를 한 copy씩 저장하고 업데이트해야 한다는 문제가 있다. 특히, 언어모델의 parameter 수가 점점 커지면서, 더 큰 비용을 야기한다.
[Fine-Tuning 문제 해결]
- 이는 자연스럽게 fine-tuning 과정을 경량화하는 방법이 제기되었다.
- 전체 parameter를 update 하는 것이 아닌, pretrained model을 고정해 놓고, 적은 양의 paramter만을 추가하여 model을 학습하는 방법이 등장하였다. (adapter-tuning)
- 이런 경향이 계속되어, GPT-3에서는 task-specific tuning 없이, user가 요청에 대한 몇 가지 sample을 같이 제공하는 in-context learning & prompting 같은 방법이 제시되었다.
[Prefix-Tuning]
- 이 논문에서는 prefix-tuning이라는 prompting에서 영감을 받은 방법을 제시한다.
- Prefix-tuning에서는 prefix라는 continuous task-specific vector를 input으로 같이 활용하여 "virtual token"의 기능을 할 수 있도록 한다.
- 이 virtual token은 실제 token과는 다른 개념으로 학습 가능한 parameter 만으로 구성되어 있다.
- Prefix tuning에서는 각 task에 따라, 각기 다른 prefix만을 학습하면 되기 때문에, 적은 양의 parameter만 학습하면 되고, 이에 따른 overhead도 매우 적다.
- 또한, Fine-tuning과 달리 prefix tuning은 user에 따라 각기 다른 prefix를 관리하면 되기 때문에, 다른 user 간의 data가 섞여서 오염되는 현상이 발생하지 않는다. 따라서, 한 batch에서 여러 user와 task를 학습할 수 있어 효율적이다.
[실험]
- Prefix-tuning의 실험을 위해, GPT-2에서 table-to-text 생성과 BART에서 text 요약을 실험했다.
- 용량 관점에서 prefix-tuining은 fine-tuning에 비해 1000배 적은 parameter만을 사용했다.
- 성능 측면에서는 table-to-text에서는 fine-tuning과 거의 비슷한 성능을 보여주었고, text 요약에서는 약간의 성능 하락만 존재하였다.
- 학습 때 보지 못한 주제들을 다루는 경우들에 대해서는 오히려 좋은 성능을 보이기도 했다.
Prefix-Tuning
- Prefix Tuning은 prompting에서 영감을 받았기 때문에, prompting에 대한 이해가 필요하다.
[Intuition]
- Prompting은 언어모델에서 model parameter 수정 없이 적절한 context를 제공해 주면, 언어모델이 원하는 결과를 제공하도록 조종할 수 있는 방법이다.
- 예를 들어, "오바마"라는 단어를 생성하고 싶을 때, 언어모델에 "버락"이라는 단어를 input으로 주면, 그 단어 뒤에 나올 가장 확률 높은 단어 "오바마"를 출력하는 것과 같다.
- 이 개념을 확장하면, 자연어 생성 task에서 언어모델에 우리가 원하는 결과를 얻도록 조종할 수 있다.
- 하지만, prompting에 문제가 있는데, 원하는 결과를 위한 context가 존재하는지에 대해 명확하지 않다.
- 어떤 context가 결과를 낼 수도 있고, 결과를 못 낼 수 도 있다.
- Data를 활용한 optimization이 도움이 될 수 있지만, discrete optimization(token은 discrete 하기 때문)은 학습이 매우 어렵다.
- Discrete token을 이용한 optimize보다, 논문에서는 continuous word embedding 단에서 instruction을 optimize 하는 방법을 선택하였다.
- 이런 방법이 실제 단어와의 matching을 요하는 token 단에서 생성한 prompt보다 더 명확한 표현이 가능하다.
- 이렇게 word embedding 단에서 instruction을 주는 방법보다, activation 단의 각 layer에서 guide를 제공하는 방법이 긴 범위의 dependency를 고려할 수 있기 때문에 효과적이다.
- 따라서, prefix-tuning에서는 모든 layer에서 prefix를 optimize 한다.
[Method]
- Prefix-tuning은 1) autoregresive LM에서 input으로 같이 제공, 2) encoder와 결과에 각각 같이 포함할 수 있다.

- Autoregressive model에서 model의 parameter는 아래와 같이 정해진다. 여기서, Pθ는 (prefix 길이) X (hi의 dimension)의 matrix로 초기화된다.

- 학습의 목표는 fine-tuning과 동일하지만, 학습해야 할 parameter가 달라진다. LM의 ϕ는 고정 후, θ만 학습한다.
- i가 prefix에 존재하면(prefix index 위치이면), hi는 Pθ의 값을 그대로 copy 하면 된다.
- 만약, i가 prefix index에 포함되지 않는 경우에도, hi는 Pθ에 의존하게 된다. (prefix는 항상 입력값의 왼쪽에 붙기 때문에 오른쪽에 영향을 미치기 때문이다.→ 왼쪽에서 오른쪽으로 token이 처리되기 때문) 즉, i가 prefix index에 없더라도, prefix가 영향을 미치게 된다.
[Parameterization of Pθ ]
- 경험적으로 Pθ parameter를 바로 update 하는 것은 불안정한 optimization을 이끌어 성능하락으로 이어진다.
- 따라서, Pθ matrix를 MLP layer들을 거쳐, reparametrize 한다. 이때, reparametrization의 결과로 나온 P'θ는 row 수는 유지하면서 (prefix length) 다른 column dimension을 가지도록 한다. (table-to-text는 512, summarization은 800)
실험 결과
[Table-to-text Generation]
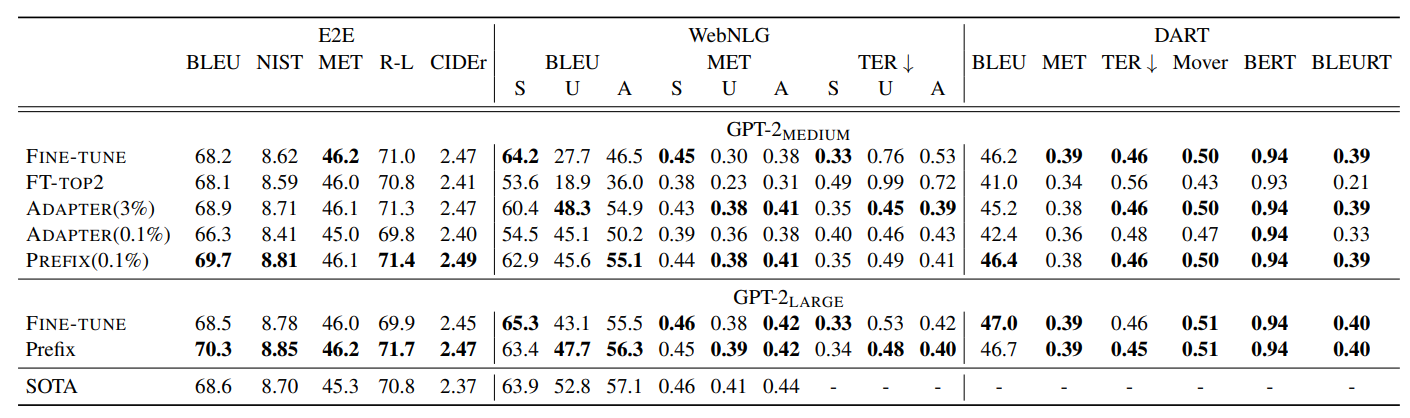
- GPT-2 model 환경에서 E2E, WebNLG, DART dataset에서 실험했다.
- Pretrained model의 0.1%의 task-specific parameter를 사용하였다.
- Prefix-tuning은 다른 lightweight tuning 방법보다 좋은 performance를 달성했고, fine-tuning에 버금가는 좋은 성능을 보였다.
- 공평한 비교를 위해, 동일 parameter 양(0.1%)을 사용한 adapter tuning과 비교해 봤을 때, dataset 당 평균 4.1 BLEU 성능 향상이 있는 것을 보였다.
- 더 많은 parameter 양(3%)을 사용한 adapter tuning이나 fine-tuning(100%)과 비교해도, prefix tuning은 거의 비슷하거나 좋은 성능을 보였다.
- 이것은 prefix tuning에서 학습한 parameter가 더 효과적으로 정보를 가지고 있음을 의미하는 것이다.
- 추가적으로, DART에서 prefix-tuning의 좋은 성능ㅇ느 다양한 domain들과 넓은 범위의 관계들에서 prefix tuning의 효과성을 보여준다.
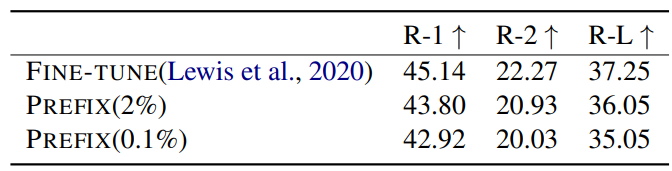
[Summrization]
- Prefix-tuning은 0.1% parameter 추가만으로 fine tuning에 비해 약간만 낮은 ROUGE-L을 보인다.
Reference
LI, Xiang Lisa; LIANG, Percy. Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190, 2021.



