반응형
GQA 배경 설명
- GQA는 2023년에 발표된 논문이다.
- GQA는 llama 2에서 도입된 기술로 유명하다.
- language model에서 transformer의 multi-head attention 구조 때문에, inference 시간이 너무 오래 걸린다는 문제가 있었고, 이를 해결하기 위한 방법을 제시하였다. (사실, 전에 등장한 multi-query attention과 multi-head attention 방식의 절충안을 제시한 논문이다.)
- 최근에는 당연하게 받아들여져, 대규모 AI 모델에는 당연하게 사용된다고 한다.
Abstract
- Multi-query attention(MQA)는 하나의 key-value head를 사용하여 decoder의 inference 시간을 줄인다.
- 하지만, MQA는 model 성능 하락이 일어날 수 있다.
- 이 논문에서는 기존의 multi-head 언어 모델의 checkpoint들을 MQA 기능을 갖춘 모델로 변경하는 방법을 제안하여, pre-training 과정의 5% 정도의 계산량만 사용하도록 한다.
- 또한, grouped-query attention(GQA)라는 multi-query attention을 일반화하여 몇 개의 key-value head로 사용할 수 있는 개념을 소개한다.
- GQA는 multi-head attention의 성능에 필적하면서도, MQA에 비견될 수 있는 빠른 속도를 가진다.
Introduction
[문제]
- Autoregressive decoder의 inference에는 각 decoding step마다, attention key, value와 decoder weights를 memory에 load 해야 하기 때문에 memory bandwidth에 의한 overhead를 겪는다.
→ Decoder의 문장을 생성할 때는 token 하나 하나를 생성하기 때문에, 그때마다 decoder의 weight와 attention 사이의 연산을 위해, memory 상에 올리는 과정을 겪는데, 이것이 문장 생성등에 속도 저하 요인이라는 것이다.
- 이런 memory bandwidth에 의한 속도 저하는 multi-query attention(MQA)이라는 query를 여러 개 사용하지만, 단일 key와 value head를 사용하는 방법에 의해 개선될 수 있다.
- 하지만, MQA를 사용하게 되면, 성능 저하와 학습 불안정성이 생기게 된다. 또한, 공개된(그 당시) 언어 모델들은 거의 모두 multi-head attention을 사용하여 학습했기 때문에, MQA를 사용하지 못한다.
[Contribution]
- 이 논문에서는 2가지 contribution을 주장한다.
- multi head attention(MHA)를 통해 학습된 언어 모델의 checkpoins를 최초 학습에 비해 적은 양의 연산만으로 MQA를 사용할 수 있도록 한다. 이로 인해, MHA의 좋은 성능을 유지하면서, 빠르게 inference 할 수 있도록 한다.
- grouped-query attention(GQA)라는 multi-head와 multi-query attention을 아우를 수 있도록 query head 당 key value 여러 개를 할당하는 방식을 소개한다. GQS는 multi head attention과 비슷한 성능을 내면서, multi-query attention처럼 빠른 속도를 가진다.
Method
[Uptraining]
- multi-head model로 부터 multi-query를 생성하는 것은 2가지 과정을 거친다.
- checkpoint를 변경한다.
- 새로운 구조에 맞게 추가적인 pre-training을 진행한다.
- 우선, 아래 그림처럼, key, value head들을 mean pooling을 통해, 하나의 vector로 만든다. (단순 여러 개중 하나를 뽑는 당식이나, 처음부터 하나의 key, value를 하는 방식보다 좋은 성능을 가진다고 한다.)

- mean pooling을 진행하는 구조를 추가한 뒤, 전체 모델 중, α 비율만큼을 기존 pre-training과 동일한 방법으로 update 한다.
[Grouped-query attention]
- Grouped-query attention은 query head들을 G개의 group으로 나눈다.
- 각 group들을 하나의 key head와 value head를 공유한다.
- 일반화를 위해서 G개의 group으로 나눈 GQA를 GQA-G로 명명하는데, G=1일 때는 MQA와 동일하고, G=Head 수 일 때는 MHA와 동일하다.
- multi-head attention 구조의 checkpoint를 GQA 방식으로 바꾸자 할 때는 group 내의 head들에 mean pooling 방식을 이용하여 Group 화하여 사용한다.
- 1~Head 개수 사이의 중간 값의 Group을 가지는 GQA는 MQA보다는 좋은 성능을 보이면서, MHA보다 빠르다.
- 이때, Group의 수를 적절히 설정하면, memory bandwidth를 넘지 않는 값을 선택할 수 있어, 속도도 MQA와 거의 비슷할 정도의 좋은 값을 가진다.

Experiments
[메인 실험]
- multi-head 구조인 T5 Large, T5 XXL로 실험하였다. uptraining을 위한 checkpoint는 공개된 T5의 checkpoint들을 사용했다.
- α 는 0.05를 사용했다. (parameter의 5%만 재 학습)
- 아래 그래프에서 볼 수 있듯, GQA를 사용한 모델은 MHA 방식에 비해 성능의 약간 하락이 있었지만, 속도가 매우 빠르고, 좋은 성능을 유지한다.
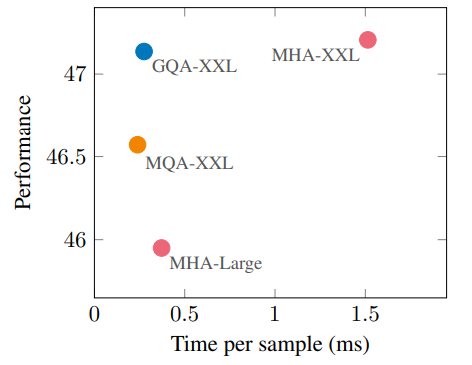

[Sub 실험]
- multi-head 구조에서 group화 방식에 따른 성능 비교 : Mean pooling 방식이 group 내에서 첫 번째 head를 사용하거나, 초기화하여 재학습하는 방식보다 더 좋은 성능을 보인다.

- α에 따른 성능 비교 : 전체의 5% 정도만 재학습해도 좋은 성능을 유지한다.

- Group 개수에 따른 속도 비교 : group 수를 적게 하면 MQA 정도의 속도가 나온다(다만, 성능은 떨어질 것이다.)

Reference
Ainslie, Joshua, et al. "Gqa: Training generalized multi-query transformer models from multi-head checkpoints." arXiv preprint arXiv:2305.13245 (2023).
'NLP 논문' 카테고리의 다른 글
| Toolformer : Language Models Can Teach Themselves to Use tools 논문 리뷰 (4) | 2025.07.17 |
|---|---|
| Prefix-Tuning: Optimizing Continuous Prompts for Generation 논문 리뷰 (1) | 2024.08.06 |
| LoRA: Low-Rank Adaptation of Large Language Models 논문 리뷰 (27) | 2024.07.30 |
| BitNet: Scaling 1-bit Transformers for Large Language Models 논문 리뷰 (24) | 2024.03.26 |
| LLaVA: Vision Instruction Turing 논문 리뷰 (41) | 2023.10.15 |



