반응형
Toolformer 배경 설명
- Toolformer는 2023년 NeurIPS에 발표된 논문으로, LLM이 외부 도구(API)를 자율적으로 사용할 수 있도록 활용하는 방법을 제시한다.
- Toolformer는 LLM이 외부 도구를 직접 조합해서 행동한다는 흐름을 개척한데 그 의의가 있다.
Abstract
- 언어모델은 텍스트를 처리하는데 뛰어난 성능을 보이지만, 역설적이게도 간단한 연산이나 사실 확인등에서 어려움을 겪는다.
- 이 논문에서는 스스로 간단한 API 형태로 외부 도구를 사용하는 방법을 배우고, 이를 활용해, 텍스트와 연산 모두를 잘 처리하는 언어모델을 제시한다.
- 논문에서 소개하는 Toolformer는 모델이 어느 API를 어느 상황에, 어떤 인자를 활용하여, 결과를 최적으로 조합할 수 있을지를 학습한다.
- 이 과정은 자기 지도학습을 통해 진행되고, 학습 과정에 각 API에 대한 별도의 설명을 필요로 하지 않는다.
- 이 연구에서는 계산기, Q&A 시스템, 검색 엔진, 번역기, 달력 등의 외부 도구들을 연결하여 다양한 downstream task에서 Toolformer가 좋은 성능을 보이는 것을 확인했다.
Introduction
[언어 모델에서 외부 도구 활용 한계]
- 언어모델은 텍스트 처리에서는 좋은 성능을 보이지만, 몇가지 한계가 있어 확장성에 한계를 가진다. (최근 데이터 활용 불가, 하루네이션, 소스가 적은 언어에서 성능이 떨어짐, 정확성을 요하는 수학에 약함.)
- 이 한계를 해결하기 위한 가장 쉬운 방법은 검색엔진이나 계산기 등의 외부 도구들을 활용하는 것이다.
- 하지만, 기존 외부 도구들을 활용한 방법들은 그 활용 방법을 인간의 주석에 의존하거나, 특정 task에만 특정 도구를 사용할 수 있는 등 광범위한 활용을 제한한다.
[논문 소개]
- 이 논문에서는 Toolformer라는 외부 도구를 사용할 수 있는 새로운 방법을 제안한다.
- 외부 도구를 사용하는 방식은 인간의 주석없이 자기 지도학습을 통해 학습된다. 이 방식은 단순 인간의 cost 측면뿐 아니라, 인간과 모델이 중요하게 생각하는 부분이 다를 수 있기 때문에 중요하다.
- 언어 모델은 generality를 잃으면 안되고, 어떤 도구를 어떻게 사용할 것인지를 스스로 결정해야 한다. 이것은 기존 방식과 달리, 도구의 활용을 특정 task에만 한정 짓지 않는다.
- 이 연구에서는 사람이 작성한 예시를 바탕으로 언어모델이 거대 언어 데이터셋 전체에서 잠재적인 API 호출을 주석달게한다. 그다음 자기 지도학습을 사용하여, API 호출 중 어떤 것이 모델이 향후 토큰을 예측하는데 도움이 되는지를 판단하도록 한다. 마지막으로, 모델이 스스로 유용하다고 생각하는 API 호출을 finetuning 한다.
- 이런 방식은 사용하는 데이터셋에 독립적이기 때문에, 모델 훈련에 사용했던 데이터셋에도 적용 가능하다. 이것은 모델이 generality와 언어모델 성능을 잃지 않는다는 것을 의미한다.
[실험]
- 논문에서는 방법의 효과를 증명하기 위해, 다양한 downstream task들에 Toolformer를 실험하였다. GPT-J 모델을 base 모델로 사용하여 더 큰 규모의 GPT-3 모델을 압도하였다.
Approach
- 모델의 목적은 언어모델이 API 요청의 의미에 따라 필요한 각기 다른 API 호출을 하도록 구성하는 것이다.
- 각 API의 input과 output은 text sequence로 표현할 수 있어야한다. 이로 인해, API 호출의 시작과 끝에 특별한 토큰을 부여하여, 어떤 텍스트에도 자연스럽게 API 호출을 삽입할 수 있게 하기 위해서이다.
- 일반 텍스트로 이뤄진 데이터셋이 있을때, 이 데이터를 API 호출이 포함된 새로운 데이터로 바꾸기 위해 다음의 세 단계를 거친다.
- 언어 모델이 문장을 모고 어느 API를 호출할 수 있을지 여러 가능성을 뽑는다.
- 뽑아낸 API들을 실제로 실행한다.
- 실행 결과가 다음 등장할 tooken을 예측하는데 도움 되는지를 확인하고, 도움 되는 경우에는 살려두고 그렇지 않으면 버린다.
- 이 과정을 통해 만들어진 데이터셋을 활용하여 모델을 다시 학습시킨다.
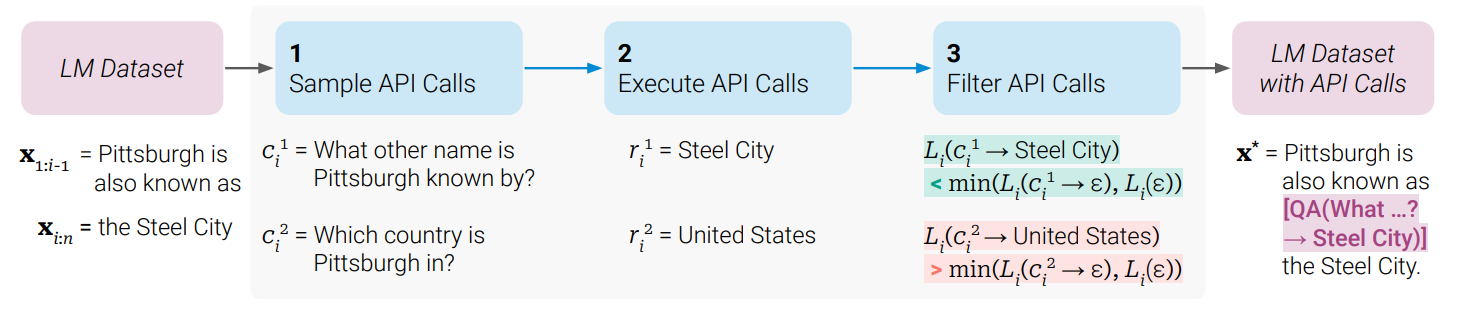
(위 과정 상세 설명)
1. Sampling API Calls
- 각 API마다 언어모델이 예제 문장에 API 호출을 달도록 유도하는 프롬프트를 작성한다.
- 언어 모델 M이 sequence (z1, z2, ...,z2,..., zn)의 다음 token으로 z(n+1)을 생성할 확률을 p_M(z(n+1)|z1, z2,..., zn)이라고 할 때, 먼저 API 호출을 수행할 수 있는 후보 위치를 최대 k개까지 샘플링한다. 이때 각 위치 i (1~n까지)에 대해 다음과 같은 방식으로 확률을 계산한다.
pi = pM( | P(x), x1:i−1)
- sampling threshold τs가 주어졌을 때, 해당 threshold를 넘는 위치만 보존하고, 만약 남는 위치가 k개를 넘어선다면, top-k만 활용한다.
- 각 API 호출들은 모델로 부터 샘플링하여 생성된다.
2. Executing API Calls
- 다음 단계로 모든 API 호출을 실제로 실행해서 그에 해당하는 응답 결과를 얻는다.
- 실행 방법은 API의 종류에 따라 전적으로 달라진다. 다만, API 호출 모두는 그 응답은 하나의 텍스트 문자열 형태를 가져야 한다.
3. Filtering API Calls
- i 위치에서 API 호출 ci에 대해, ri를 API의 호출, w를 각 sequence의 weight라고 한다면, i 이후 위치의 token을 예측하는데 모델의 어려움을 weighted cross-entropy 식으로 아래처럼 정의할 수 있다.

- 해당 손실함수를 1) API 호출과 그 결과를 둘 다 알려줬을 때, 2) API 호출을 하지 않거나, 호출만 하고 결과를 안 알려줬을 때 두 상황에 모두 구하고,

- API 호출의 결과까지 넣지 않은 경우에 넣은 것보다 특정 thereshold τf만큼 손실함수가 큰 값들을 살려둔다.

Modeling Finetuning
- 위의 세 단계를 거쳐, 원래 데이터셋에 효과가 있는 API 호출만 살려둔 데이터셋이 만들어진다.
- 이를 모델에 다시 finetuning 하여, 실제 효과 있는 부분에서만 API 호출과 응답을 추가된 상태에서 학습하게 된다.
- 이를 통해, 모델은 어떤 도구(API)를 언제, 어떻게 사용할지 스스로 판단하는 능력을 키울 수 있게 된다.
Tools
- 다양한 도구의 활용을 관찰하기 위해, 여러 가지 도구들을 사용한다.
- 각 도구에 대한 유일한 제한은 2가지이다. 1) 입력과 출력을 텍스트 형태로 표현 가능해야 하고, 2) 해당 도구의 사용 예시를 몇 가지 제공할 수 있어야 한다.
- 논문에서는 아래 5가지 도구를 사용한다.
- 질문 응답 시스템 : 검색 기반 언어 모델
- 계산기 : 수치 계산을 수행
- 위키 백과 검색(검색 엔진) : 모델의 사실 추출, BM25를 사용
- 기계 번역 시스템 : 언어 번역 능
- 달력 : 시간적 맥락을 보완
Experiments
1. 질문 응답
- Toolformer는 동일 크기의 GPT-J보다 최대 +18.6 성능 향상
- 모델 크기가 더 큰 GPT-3(175B)보다 성능이 뛰어난 경우가 있음.
- 대부분의 경우 Toolformer는 질문 응답 API를 활용하여 정확도를 높임

2. 수학 문제 풀이
- ASDiv, SVAMP, MAWPS에서 Toolformer는 계산기 API를 활용해 GPT-3(175B)를 크게 능가하였다. (예: MAWPS 19.8 → 44.0)
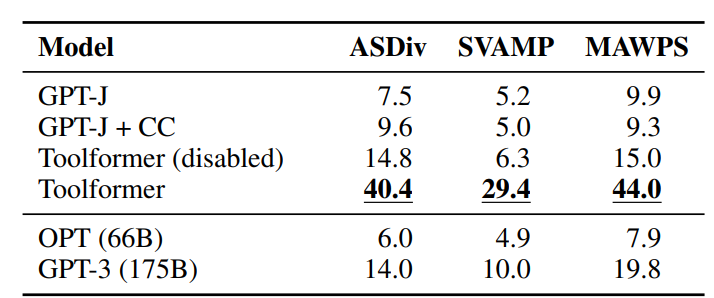
3. QA 데이터셋
- WebQuestions, TriviaQA 등에서는 위키백과 검색 API를 사용하여 성능이 고르게 향상되었으나, GPT-3보다는 다소 낮다.

4. 다국어 QA(MLQA)
- 번역 API를 활용해 성능 향상, 특히 저자원 언어에서 효과적이다.
- 단, 일부 언어에서는 CCNet 기반 미세조정이 성능 저하를 유발하기도 한다.

5. 시간 인식 (TEMPLAMA, DATESET)
- Toolformer는 DATESET에서 달력 API 사용으로 큰 향상을 이루었다.(+23.4pt).
- 하지만 TEMPLAMA에서는 API보다 검색/QA 툴을 더 자주 사용한다.

언어 모델링 성능 영향
- API가 포함된 데이터셋(C*)으로 학습해도, API를 사용하지 않을 때 기존 GPT-J의 언어 모델링 성능(perplexity)과 비슷하다. → 성능 저하 없음.
스케일링 법칙
- 작은 모델(예: GPT-2 124M)은 API 호출을 잘 활용하지 못하지만, 775M 이상부터 효과가 뚜렷하게 나타난다.모델 크기가 커질수록 API 호출을 더 적절히 활용하게 됨을 의미)



