반응형
논문 배경 설명
- Large Language Models are Zero-Shot Reasoners 논문은 2022년 NeuIPS에 발표된 논문이다.
- 기존 CoT Prompting에서 task 별 prompt 설계와 사람이 개입한 예제 추출을 간단한 트리거 prompt만으로 대체하여 성능 향상을 보였고, zero-shot 개념의 prompt로 확장 가능성을 크게 늘렸다.
Abstract
- NLP에서 CoT prompting 방식은 복잡한 문제를 각 단계들로 나눠서 추론하는 방식을 사용하여, 연산, 기호 추론 등 복잡한 문제에서 좋은 효과를 입증했다.
- 이런 CoT prompting의 성능은 LLM의 few-shot 학습 능력 덕분이라고 여겨지지만, 이 논문에서는 각 답변에 "Let's think step by step"이라는 단순한 문구를 추가하는 것만으로도 LLM이 좋은 zero-shot 추론 능력을 지닌다는 것을 보인다.
- 실험 결과에서 논문의 zero-shot CoT가 별도의 예시 없이, 다양한 연산, 기호 추론, 다른 논리적 추론 벤치마크에서 zero-shot LLM의 성능을 월등히 앞서는 것을 보인다.
Introduction
[CoT prompting]
- LLM의 좋은 성능은 모델 크기뿐 아니라, few-shot 혹은 zero-shot 학습의 효과로 여겨졌고, 이로인해, 간단한 몇 개의 예시나 instruction을 제공하는 것만으로도 다양한 문제를 풀 수 있다.
- 모델에 이런 조건을 주는 것을 prompting이라고 하고, 다양한 prompting 구성의 방법이 NLP의 주요 관심사가 되었다.
- LLM은 간단하고 직관적인 문제들을 풀때는 task-specific 한 few-shot이나 zero-shot prompting 만으로 쉽게 해결하지만, 논리적 연산이 필요한 문제들에 대해서는 어려움을 겪곤 한다.
- 이를 해결하기 위해, CoT prompting이라는 어려운 문제를 푸는 추론 과정을 예시로 제공하여 문제를 해결하는 방법이 등장하였고, 추론 문제에서 큰 성능 향상을 보였다.
[논문 소개]
- CoT prompting의 성공과 다른 task-specific prompting 작업들이 LLM의 few-shot 학습 능력에서 비롯되었다고 생각되지만, 이 논문에서는 간단한 "Let's think step by step"이라는 zero-shot-CoT prompt를 추가하여 추론 능력을 크게 향상하는 효과를 보인다.
- 이 방법은 매우 간단하지만, 풍부한 추론 과정을 zero-shot 방식으로 만들어주고, 문제를 정확한 정답에 도달할 수 있게 한다
- 이 방법이 중요한 것은 기존 task-specific prompt 들과 달리, task에 종속적이지 않고, 유연하다.
[실험]
- zero-shot-CoT의 효과를 입증하기 위해 다른 prompting baseline과 비교하였고, 정교하게 짜인 task-specific prompting보다는 떨어지지만, 기존 zero-shot 방식을 크게 앞서는 성능을 보인다.
- 또한, 이 논문에서 제안된 특정 prompt를 사용하는 경우, zero-shot-CoT는 few-shot CoT와 필적할만한 좋은 성능을 보이는데, 이는 task 별 추론 과정을 설계해야 하는 few-shot 방식의 한계를 극복하면서도 좋은 성능을 보여 다양한 task에 확장 가능함을 보인다.
Zero-shot Chain of Thought
- 논문에서는 Zero-shot-CoT를 제안한다. 이 방법은 기존 CoT prompting과 다르게 추론 과정의 예시 샘플이 필요하지 않다.
- 따라서, 범용적으로 사용 가능하고, 하나의 템플릿은 여러 task에 공통으로 적용 가능하다.
- 핵심 아이디어는 매우 간단한데, 추론 과정을 이끌기 위해, "Let's think step by step"이나 이와 비슷한 문구를 prompt에 추가하는 것이다.

[Two-stage prompting]
- Zero-shot-CoT는 개념적으로 매우 간단하지만, prompting을 추론과정과 응답과정 두 번에 걸쳐 사용해야 한다.
- 단순 응답만 요구하는 zero-shot 방식이나, 예시에 애초에 응답만 요구하는 방식을 넣어 응답을 얻는 few-shot 방식과의 차이인데, 추론을 요구하는 과정과 정답을 요구하는 과정으로 나뉜다.
- 1st prompting, 추론 추출 과정 : "Q: [X], A: [T]"와 같은 prompt(X')을 구성하고, X에 요청할 질문을 T에 "Let's think step by step"과 같은 추론을 요구하는 문장을 넣는다. 이렇게 만들어진 prompt를 LLM의 input으로 활용하여 결과 Z를 얻는다.
- 2nd prompting, 정답 추출 과정 : 두 번째 단계에서는 첫 번째 단계에서 만든 문장과 LLM의 output을 결합하여, "[X'] [Z] [A]"라는 prompt를 만든다. 정답을 얻기 위해, 마지막에 정답을 요구하는 질문 형식의 문장을 추가한다.

Experiment
Task and Datasets
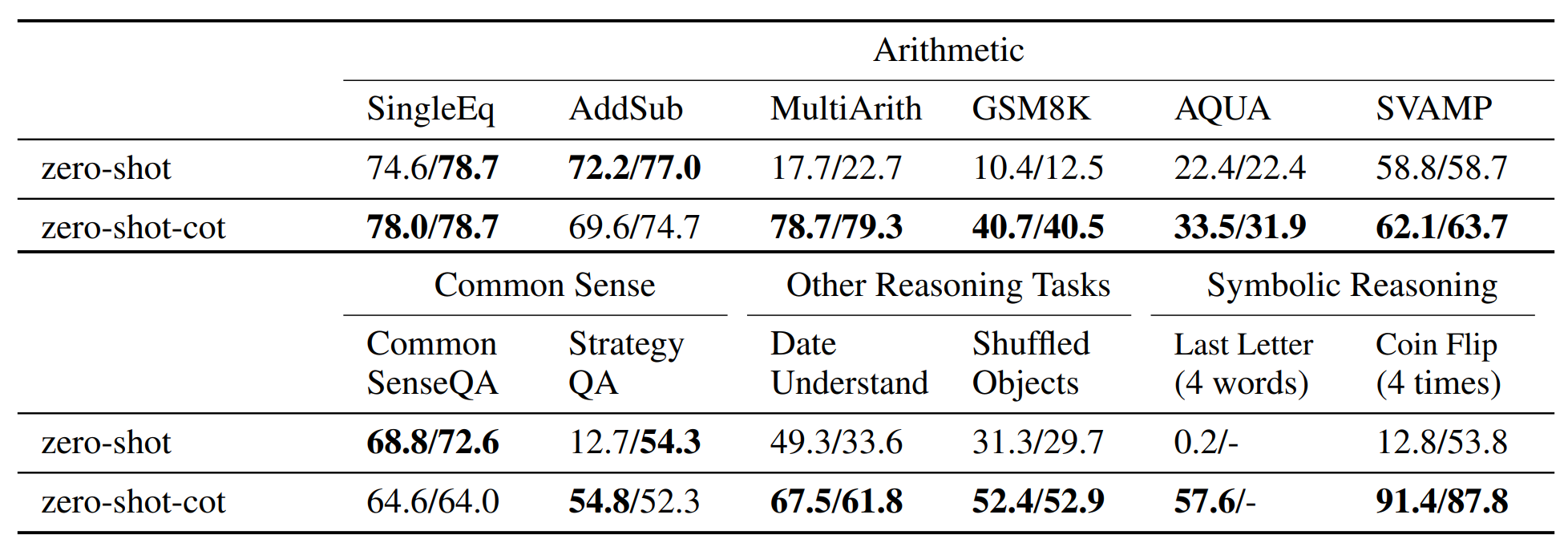
- 총 12개 데이터셋, 연산, 상식, 기호 추론, 기타 논리 추론의 4가지 유형을 평가
Model
- 총 17개 언어 모델 실험 : GPT-3 계열(InstructGPT, vanilla), PaLM 등
- 모델 크기는 0.3B부터 540B까지
Baseline 평가 방식
- 비교 대상 : Zero-shot, Few-shot, Few-shot-CoT
- 모든 방식에서 일관된 greedy decoding 사용, Few-shot 방식은 예제 순서에 따른 편차를 줄이기 위해 고정된 seed로 단 1회 실행
결과 요약
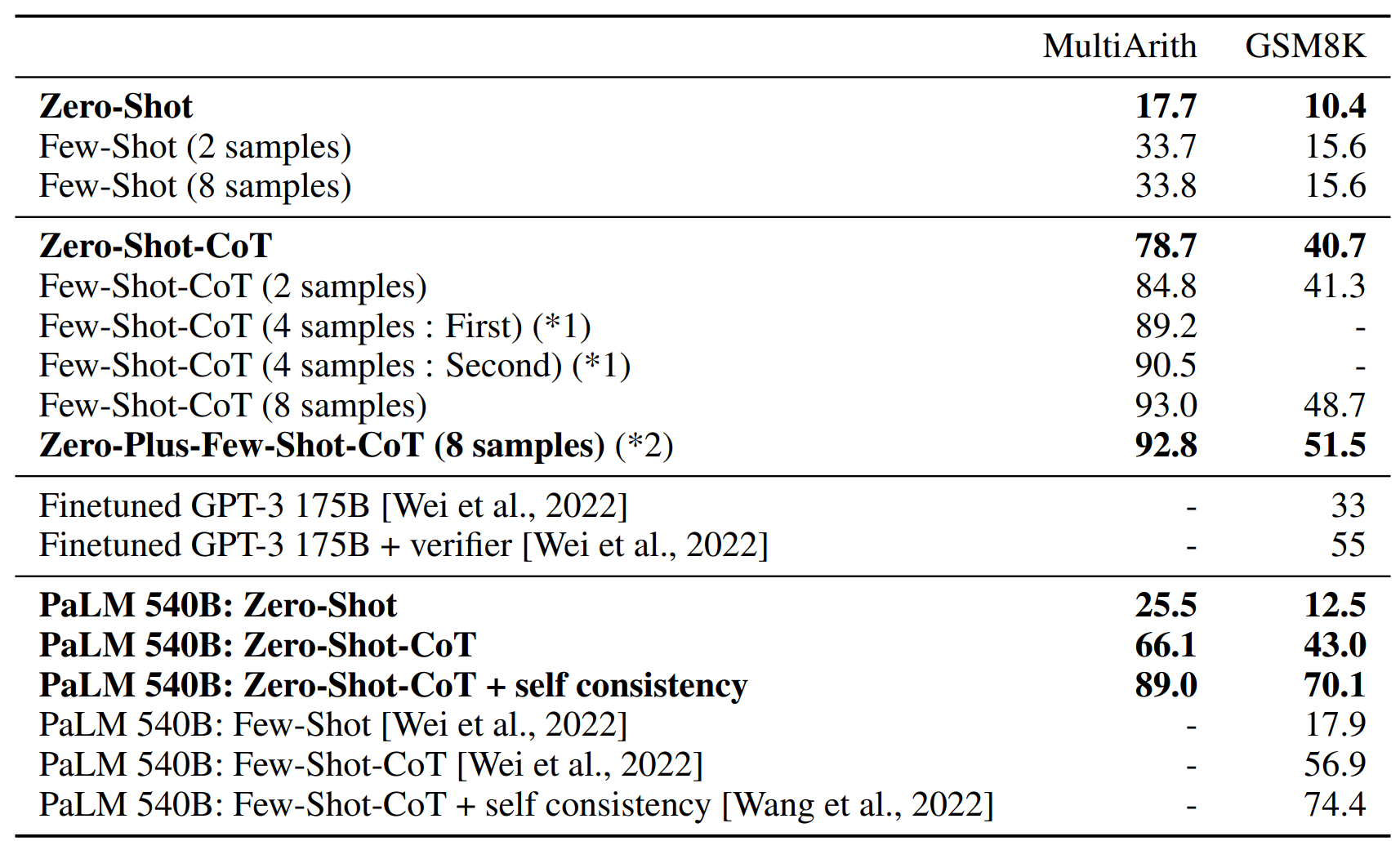
- Zero-shot-CoT는 다중 단계 추론이 필요한 산술 문제(MultiArith, GSM8K 등)에서 매우 큰 성능 향상을 보임 (MultiArith 17.7% → 78.7%, GSM8K: 10.4% → 40.7%)
- 모델 크기 증가 시 Zero-shot-CoT는 매우 크게 성능이 향상된다.
- 템플릿은 "Let's think step by step"이 가장 높은 성능을 기록했고, 잘못된 prompt는 오히려 성능을 낮춘다.